
لدعم لوحة بيانات الدمج المستمر التي يمكن توسيع نطاقها وتحسين أدائها ومرونتها، يجب تصميم الخلفية في لوحة بيانات VTS بعناية مع فهم عميق لوظائف قاعدة البيانات. Google Cloud Datastore هي قاعدة بيانات NoSQL تقدّم ضمانات ACID للمعاملات و الاتساق النهائي بالإضافة إلى اتساق قوي داخل مجموعات الكيانات. ومع ذلك، تختلف البنية كثيرًا عن قواعد بيانات SQL (وحتى عن قاعدة بيانات Bigtable في السحابة الإلكترونية). فبدلاً من الجداول والصفوف والخلايا، تتضمّن البنية أنواعًا وكيانات وخصائص.
توضّح الأقسام التالية بنية البيانات وأنماط طلب البيانات ل إنشاء واجهة خلفية فعّالة لخدمة الويب VTS Dashboard.
عدد العناصر
تخزِّن الكيانات التالية الملخّصات والمراجع من عمليات تشغيل اختبار VTS:
- كيان الاختبار: تخزِّن البيانات الوصفية حول عمليات تنفيذ اختبار معيّن. مفتاحها هو اسم الاختبار وتشمل خصائصه عدد حالات الانهيار وعدد حالات النجاح وقائمة حالات تعطُّل نموذج الاختبار منذ تعديلها من خلال مهام التنبيهات.
- كيان التشغيل التجريبي يحتوي على بيانات وصفية من عمليات تنفيذ اختبار معيّن. يجب أن يخزن الطابع الزمني لبدء الاختبار وانتهائه، وملف تعريف الإصدار للاختبار، وعدد حالات الاختبار التي نجحت والتي تعذّر إكمالها، ونوع التشغيل (مثل التشغيل قبل الإرسال أو بعد الإرسال أو على الجهاز المحلي)، وقائمة بروابط السجلّات، واسم الجهاز المضيف، وعدد ملخّصات التغطية.
- عنصر معلومات الجهاز يحتوي على تفاصيل حول الأجهزة المستخدَمة أثناء إجراء الاختبار. ويشمل معرّف إصدار الجهاز واسم المنتج ومعلومات عن إصدار الإصدار والفرع وABI. ويتم تخزين هذا العنصر بشكل منفصل عن عنصر عملية الاختبار لتتمكّن من إجراء عمليات اختبار على أجهزة متعددة بطريقة من واحد إلى عدة أجهزة.
- Profiling Point Run Entity (كيان نقطة بدء التحليل) يلخِّص هذا التقرير البيانات التي تم جمعها لنقطة ملف تعريف معيّنة خلال عملية إجراء اختبار. ويوضّح تصنيفات محور البيانات واسم نقطة التحليل والقيم والنوع ووضع الانحدار لبيانات التحليل.
- كيان التغطية: يصف بيانات التغطية التي تم جمعها لملف واحد. يحتوي على معلومات مشروع Git ومسار الملف وقائمة أعداد التغطية لكل سطر في الملف المصدر.
- كيان تنفيذ نموذج الاختبار يصف هذا العمود نتيجة أحد حالات الاختبار المحدّدة من عملية إجراء اختبار، بما في ذلك اسم حالة الاختبار ونتيجة الاختبار.
- عنصر "الأماكن المفضّلة للمستخدم" يمكن تمثيل كل اشتراك مستخدم في عنصر يحتوي على إشارة إلى الاختبار ورقم تعريف المستخدم الذي تم إنشاؤه من خدمة مستخدم App Engine. يتيح ذلك إجراء عمليات بحث فعالة في الاتجاهين (أي لجميع المستخدمين المشتركين في اختبار ولجميع الاختبار التي أعجب بها أحد المستخدمين).
تجميع الكيانات
تمثّل كلّ وحدة اختبار جذر مجموعة كيانات. عناصر عمليات التشغيل التجريبية هي عناصر فرعية لهذه المجموعة وعناصر رئيسية لعناصر الأجهزة ونقاط ملف الأداء وعناصر التغطية ذات الصلة باختبار وتشغيل تجربي العلويَين.
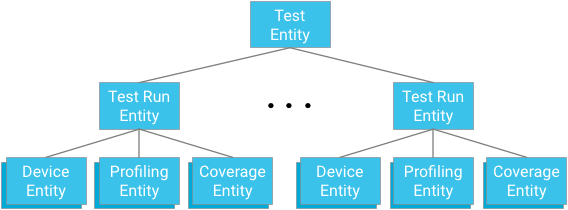
نقطة رئيسية: عند تصميم روابط الأصول، عليك موازنة الحاجة إلى توفير آليات فعالة ومتسقة للاستعلام مع القيود التي تفرضها قاعدة البيانات.
المزايا
يضمن شرط الاتساق عدم ظهور أثر المعاملة في العمليات المستقبلية إلى أن يتم تأكيدها، وأن تكون المعاملات السابقة مرئية للعمليات الحالية. في Cloud Datastore، تُنشئ تجميعات الكيانات مجموعات من عمليات القراءة والكتابة المتسقة داخل المجموعة، والتي تشمل في هذه الحالة كل عمليات الاختبار والبيانات ذات الصلة بوحدة اختبار. في ما يلي فوائد ذلك:
- يمكن التعامل مع عمليات القراءة والتعديل لحالة وحدة الاختبار من خلال وظائف التنبيهات على أنّها عمليات أساسية
- عرض متّسق مضمون لنتائج حالات الاختبار ضمن وحدات الاختبار
- إجراء عمليات بحث أسرع ضمن أشجار الأنساب
القيود
لا يُنصح بالكتابة إلى مجموعة كيانات بمعدّل أسرع من كيان واحد في الثانية، لأنّه قد يتم رفض بعض عمليات الكتابة. ما دامت مهام التنبيهات وعمليات التحميل تتم بمعدّل لا يتجاوز عملية كتابة واحدة في الثانية، تكون البنية قوية وتضمن اتساقًا قويًا.
في النهاية، يكون الحد الأقصى لكتابة واحدة لكل وحدة اختبار في الثانية معقولاً لأنّه يستغرق عادةً تنفيذ الاختبارات دقيقة واحدة على الأقل، بما في ذلك الوقت المستغرَق في تنفيذ إطار عمل VTS ، ما لم يتم تنفيذ الاختبار باستمرار في وقت واحد على أكثر من 60 مضيفًا مختلفًا، لا يمكن أن يكون هناك ازدحام في عمليات الكتابة. يصبح هذا الأمر أكثر احتمالًا نظرًا لأنّ كل وحدة هي جزء من خطة اختبار تستغرق في أغلب الأحيان أكثر من ساعة. يمكن التعامل بسهولة مع القيم الشاذة إذا كان المضيفون يجرون الاختبارات في الوقت نفسه، ما يؤدي إلى حدوث طفرات قصيرة في عمليات الكتابة إلى المضيفين نفسهم (على سبيل المثال، من خلال رصد أخطاء الكتابة وإعادة المحاولة).
اعتبارات التوسّع
لا يلزم أن يكون الاختبار هو العنصر الرئيسي لعملية تنفيذ الاختبار (على سبيل المثال، يمكنه استخدام مفتاح آخر ويكون له اسم الاختبار ووقت بدء الاختبار كسمات)، ولكن سيؤدي ذلك إلى استبدال الاتساق القوي بالاتساق النهائي. على سبيل المثال، قد لا ترى مهمة التنبيه لقطة اتّساق متبادل من أحدث عمليات تنفيذ الاختبار ضمن وحدة اختبار، ما يعني أنّ الحالة العامة قد لا تصوّر بشكل دقيق تسلسل عمليات تنفيذ الاختبار. وقد يؤثر ذلك أيضًا في عرض عمليات تنفيذ الاختبار ضمن وحدة اختبار واحدة، والتي قد لا تكون بالضرورة لقطة منتظمة لتسلسل التنفيذ. وفي النهاية، ستكون المقتطفات متسقة، ولكن لا يمكن ضمان أن تكون أحدث البيانات متسقة.
أُطُر الاختبار
ومن العوائق المحتملة الأخرى الاختبارات الكبيرة التي تتضمّن العديد من حالات الاختبار. إنّ المَعلمتَين المحدودتَين للتشغيل هما الحد الأقصى لمعدل نقل البيانات للكتابة ضمن مجموعة كيانات بمقدار معاملة واحدة في الثانية، بالإضافة إلى الحد الأقصى لحجم المعاملة الذي يبلغ 500 عنصر.
يمكن اتّباع نهج معيّن لتحديد نموذج اختبار يتضمّن عملية إجراء اختبار كعنصر أصل (على غرار طريقة تخزين بيانات التغطية وبيانات الملف الشخصي ومعلومات الجهاز ):
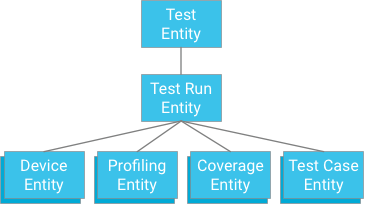
على الرغم من أنّ هذا النهج يقدّم اتساقًا ووحدة، إلا أنّه يفرض قيودًا قوية على الاختبارات: إذا كانت المعاملة تقتصر على 500 عنصر، لا يمكن أن يتضمّن الاختبار سوى 498 حالة اختبار (على افتراض عدم توفّر بيانات تغطية أو ملفّات تعريف). إذا تجاوز الاختبار هذا الحدّ، لن تتمكّن معاملة واحدة من كتابة كل نتائج حالة الاختبار دفعة واحدة، وقد يؤدي تقسيم حالات الاختبار إلى معاملات منفصلة إلى تجاوز الحدّ الأقصى لمعدل نقل البيانات لكتابة مجموعة الكيانات، وهو دورة واحدة في الثانية. لا يُنصح باستخدام هذا الحلّ لأنّه لن يتمكّن من التوسّع بشكل جيد بدون التضحية بالأداء.
ومع ذلك، بدلاً من تخزين نتائج حالات الاختبار كعناصر فرعية لمسار الاختبار، يمكن تخزين حالات الاختبار بشكل مستقل وتقديم مفاتيحها إلى مسار الاختبار (يحتوي مسار الاختبار على قائمة بالمعرّفات لعناصر حالات الاختبار):
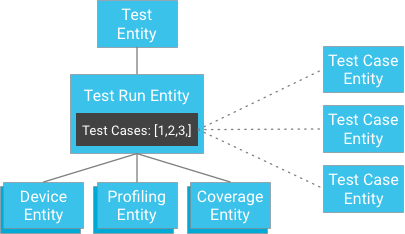
للوهلة الأولى، قد يبدو أنّ هذا يخالف ضمان الاتساق القوي. ومع ذلك، إذا كان لدى العميل عنصر تشغيل اختبار وقائمة بمعرّفات حالات الاختبار، لن يحتاج إلى إنشاء طلب بحث، بل يمكنه بدلاً من ذلك الحصول مباشرةً على حالات الاختبار من خلال معرّفاتها، والتي يُضمن دائمًا أن تكون متسقة. يخفّف هذا النهج بشكل كبير من القيود المفروضة على عدد حالات الاختبار التي قد تتضمنها عملية الاختبار، مع تحقيق اتساق قوي بدون التهديد بالكتابة المفرطة ضمن مجموعة عناصر.
أنماط الوصول إلى البيانات
تستخدِم لوحة بيانات "التتبّع في الوقت الفعلي" أنماط الوصول إلى البيانات التالية:
- أجهزة المستخدم المفضّلة يمكن البحث عنها باستخدام فلتر مساواة على عناصر المفضّلات الخاصة بالمستخدمين التي تحتوي على عنصر مستخدم App Engine معيّن كخاصية.
- البيانات الاختبارية: طلب بحث بسيط عن الكيانات الاختبارية لتقليل النطاق الترددي لعرض الصفحة الرئيسية، يمكن استخدام توقّع لعدد الاختبارات التي اجتازت الاختبار وعدد الاختبارات التي تعذّر إكمالها من أجل حذف القائمة الطويلة المحتملة لأرقام تعريف اختبارات الحالة التي تعذّر إكمالها وغيرها من البيانات الوصفية التي تستخدمها مهام التنبيهات.
- عمليات التنفيذ التجريبي: يتطلّب طلب البحث عن عناصر عمليات التشغيل التجريبية ترتيبًا حسب المفتاح (الطابع الزمني) والفلترة المحتمَلة لخصائص عمليات التشغيل التجريبية، مثل معرّف الإصدار وعدد عمليات الموافقة وما إلى ذلك. من خلال إجراء طلب بحث عن سلف باستخدام مفتاح عنصر الاختبار، تكون القراءة متسقة بشكل كبير. في هذه المرحلة، يمكن استرجاع جميع نتائج نموذج الاختبار باستخدام قائمة الأرقام التعريفية المخزّنة في خاصية "تشغيل الاختبار"، ويضمن ذلك أيضًا أن تكون النتيجة متسقة بشكل كبير بسبب طبيعة عمليات retrieving datastore.
- بيانات الملف الشخصي والتغطية: يمكن إجراء طلب بحث عن بيانات التحليل أو التغطية المرتبطة باختبار بدون استرداد أي بيانات أخرى عن عمليات تنفيذ الاختبار (مثل بيانات التحليل/التغطية الأخرى وبيانات حالات الاختبار وغيرها). سيؤدي طلب بحث سلف باستخدام مفاتيح عنصرَي الاختبار وتشغيل الاختبار إلى retrieving all profiling points recorded during the test run. ومن خلال الفلترة أيضًا على اسم نقطة التحليل أو اسم الملف، يمكن retrieving a single profiling or coverage entity. وبحكم طبيعة طلبات البحث عن الأصول، تكون هذه العملية متسقة بشكل كبير.
لمعرفة تفاصيل عن واجهة المستخدم ولقطات الشاشة لأنماط البيانات هذه أثناء استخدامها، يُرجى الاطّلاع على واجهة مستخدم لوحة بيانات مراقبة الفيديو.