
Android 8.0 enthält Binder- und hwbinder-Leistungstests für Durchsatz und Latenz. Es gibt zwar viele Szenarien, um wahrnehmbare Leistungsprobleme zu erkennen, aber das Ausführen solcher Szenarien kann zeitaufwendig sein und die Ergebnisse sind oft erst nach der Systemintegration verfügbar. Mit den bereitgestellten Leistungstests können Sie während der Entwicklung einfacher testen, schwerwiegende Probleme früher erkennen und die Nutzerfreundlichkeit verbessern.
Leistungstests umfassen die folgenden vier Kategorien:
- Binderdurchsatz (verfügbar in
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - Binder-Latenz (verfügbar in
frameworks/native/libs/binder/tests/schd-dbg.cpp) - hwbinder-Durchsatz (verfügbar in
system/libhwbinder/vts/performance/Benchmark.cpp) - hwbinder-Latenz (verfügbar in
system/libhwbinder/vts/performance/Latency.cpp)
binder und hwbinder
Binder und hwbinder sind Android-IPC-Infrastrukturen (Inter-Process Communication), die denselben Linux-Treiber verwenden, sich aber in folgenden qualitativen Aspekten unterscheiden:
| Seitenverhältnis | Ordner | hwbinder |
|---|---|---|
| Zweck | Ein allgemeines IPC-Schema für das Framework bereitstellen | Mit Hardware kommunizieren |
| Attribut | Für die Nutzung des Android-Frameworks optimiert | Niedrige Latenz bei minimalem Overhead |
| Planungsrichtlinie für Vorder-/Hintergrund ändern | Ja | Nein |
| Übergabe von Argumenten | Verwendet die vom Parcel-Objekt unterstützte Serialisierung | Verwendet Streubuffer und vermeidet den Overhead beim Kopieren von Daten, die für die Paketserialisierung erforderlich sind |
| Prioritätsübernahme | Nein | Ja |
Binder- und hwbinder-Prozesse
In einem Systrace-Visualizer werden Transaktionen so dargestellt:
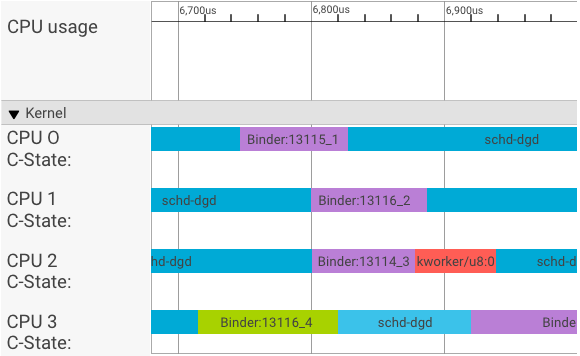
Im obigen Beispiel:
- Die vier (4) schd-dbg-Prozesse sind Clientprozesse.
- Die vier (4) Binder-Prozesse sind Serverprozesse (Name beginnt mit Binder und endet mit einer Sequenznummer).
- Ein Clientprozess ist immer mit einem Serverprozess gekoppelt, der seinem Client zugewiesen ist.
- Alle Client-Server-Prozesspaare werden vom Kernel unabhängig und gleichzeitig geplant.
Auf CPU 1 führt der Betriebssystemkernel den Client aus, um die Anfrage zu stellen. Sofern möglich, wird dann dieselbe CPU verwendet, um einen Serverprozess zu aktivieren, die Anfrage zu verarbeiten und nach Abschluss der Anfrage wieder zum ursprünglichen Kontext zurückzukehren.
Durchsatz und Latenz
Bei einer perfekten Transaktion, bei der der Client- und Serverprozess nahtlos wechselt, liefern Durchsatz- und Latenztests nicht wesentlich unterschiedliche Ergebnisse. Wenn der Betriebssystemkernel jedoch einen Interrupt-Antrag (IRQ) von der Hardware verarbeitet, auf Sperren wartet oder einfach entscheidet, eine Nachricht nicht sofort zu verarbeiten, kann sich eine Latenzblase bilden.
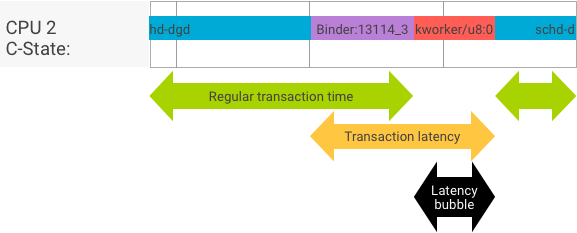
Beim Durchsatztest werden eine große Anzahl von Transaktionen mit unterschiedlichen Nutzlastgrößen generiert. So erhalten Sie eine gute Schätzung für die reguläre Transaktionszeit (im Bestfall) und den maximalen Durchsatz, den der Binder erreichen kann.
Im Gegensatz dazu werden beim Latenztest keine Aktionen an der Nutzlast ausgeführt, um die reguläre Transaktionszeit zu minimieren. Anhand der Transaktionszeit können wir den Binder-Overhead schätzen, Statistiken für den Worst-Case erstellen und das Verhältnis der Transaktionen berechnen, deren Latenz eine bestimmte Frist einhält.
Prioritätsumkehrungen behandeln
Eine Prioritätsumkehr tritt auf, wenn ein Thread mit höherer Priorität logisch auf einen Thread mit niedrigerer Priorität wartet. Bei Echtzeitanwendungen (RT) tritt das Problem der Prioritätsumkehrung auf:
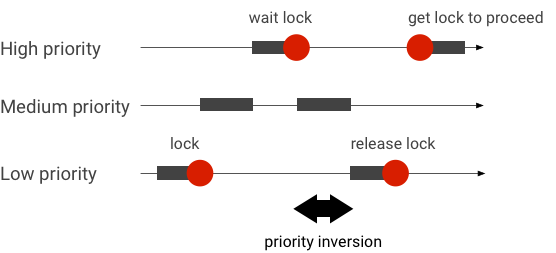
Bei der Verwendung des Linux Completely Fair Scheduler (CFS) hat ein Thread immer die Chance, ausgeführt zu werden, auch wenn andere Threads eine höhere Priorität haben. Daher behandeln Anwendungen mit CFS-Planung die Prioritätsumkehr als erwartete Funktion und nicht als Problem. Wenn das Android-Framework jedoch eine RT-Planung benötigt, um die Berechtigung für Threads mit hoher Priorität zu gewährleisten, muss die Prioritätsumkehrung behoben werden.
Beispiel für eine Prioritätsumkehrung während einer Binder-Transaktion (RT-Thread wird logisch von anderen CFS-Threads blockiert, während auf die Ausführung eines Binder-Threads gewartet wird):
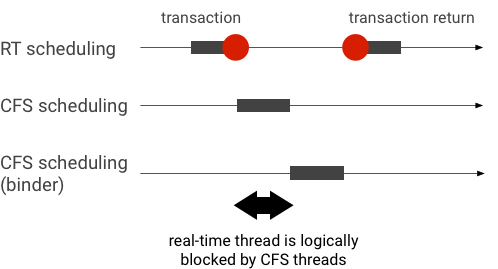
Um Blockierungen zu vermeiden, können Sie die Prioritätsübernahme verwenden, um den Binder-Thread vorübergehend zu einem RT-Thread zu eskalieren, wenn er eine Anfrage von einem RT-Client verarbeitet. Beachten Sie, dass die Ressourcen für die RT-Planung begrenzt sind und mit Bedacht verwendet werden sollten. In einem System mit n CPUs ist die maximale Anzahl der aktuellen RT-Threads ebenfalls n. Zusätzliche RT-Threads müssen möglicherweise warten (und somit ihre Fristen verpassen), wenn alle CPUs von anderen RT-Threads belegt sind.
Um alle möglichen Prioritätsumkehrungen zu beheben, können Sie die Prioritätsübernahme sowohl für den Binder als auch für den hwbinder verwenden. Da Binder jedoch im gesamten System weit verbreitet ist, kann die Aktivierung der Prioritätsübernahme für Bindertransaktionen das System mit mehr RT-Threads überlasten, als es bedienen kann.
Durchsatztests ausführen
Der Durchsatztest wird mit dem Binder/hwbinder-Transaktionsdurchsatz ausgeführt. In einem nicht überlasteten System sind Latenzblasen selten und ihre Auswirkungen können beseitigt werden, solange die Anzahl der Iterationen hoch genug ist.
- Der Durchsatztest für den Binder befindet sich in
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - Der Durchsatztest für hwbinder befindet sich in
system/libhwbinder/vts/performance/Benchmark.cpp.
Testergebnisse
Beispielergebnisse von Durchsatztests für Transaktionen mit unterschiedlichen Nutzlastgrößen:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Zeit gibt die in Echtzeit gemessene Umlaufzeit an.
- CPU gibt die Gesamtzeit an, während der CPUs für den Test geplant sind.
- Iterationen gibt an, wie oft die Testfunktion ausgeführt wurde.
Beispiel für eine Nutzlast mit 8 Byte:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… wird der maximale Durchsatz, den der Binder erreichen kann, so berechnet:
MAX. Durchsatz mit 8‑Byte-Nutzlast = (8 * 21.296) ÷ 69.974 ≈ 2,423 b/ns ≈ 2,268 Gb/s
Testoptionen
Wenn Sie Ergebnisse im JSON-Format erhalten möchten, führen Sie den Test mit dem Argument --benchmark_format=json aus:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Latenztests ausführen
Beim Latenztest wird die Zeit gemessen, die der Client benötigt, um mit der Initialisierung der Transaktion zu beginnen, zum Serverprozess für die Verarbeitung zu wechseln und das Ergebnis zu erhalten. Außerdem wird geprüft, ob bekannte fehlerhafte Verhaltensweisen des Schedulers vorliegen, die sich negativ auf die Transaktionslatenz auswirken können, z. B. ein Scheduler, der die Prioritätsübernahme nicht unterstützt oder das Synchronisierungsflag nicht berücksichtigt.
- Der Binder-Latenztest befindet sich unter
frameworks/native/libs/binder/tests/schd-dbg.cpp. - Der hwbinder-Latenztest befindet sich unter
system/libhwbinder/vts/performance/Latency.cpp.
Testergebnisse
Die Ergebnisse (in JSON) enthalten Statistiken zur durchschnittlichen/besten/schlechtesten Latenz und zur Anzahl der verpassten Fristen.
Testoptionen
Für Latenztests sind die folgenden Optionen verfügbar:
| Befehl | Beschreibung |
|---|---|
-i value |
Geben Sie die Anzahl der Iterationen an. |
-pair value |
Geben Sie die Anzahl der Prozesspaare an. |
-deadline_us 2500 |
Geben Sie die Frist in US an. |
-v |
Detaillierte Ausgabe (Debugging) abrufen |
-trace |
Die Ablaufverfolgung bei Erreichen eines Termins anhalten |
In den folgenden Abschnitten werden die einzelnen Optionen beschrieben, ihre Verwendung erläutert und Beispielergebnisse gezeigt.
Iterationen angeben
Beispiel mit einer großen Anzahl von Iterationen und deaktivierter ausführlicher Ausgabe:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Diese Testergebnisse zeigen Folgendes:
"pair":3- Erstellt ein Client- und Serverpaar.
"iterations": 5000- Umfasst 5.000 Iterationen.
"deadline_us":2500- Die Frist beträgt 2.500 µs (2,5 ms). Die meisten Transaktionen sollten diesen Wert einhalten.
"I": 10000- Eine einzelne Testiteration umfasst zwei (2) Transaktionen:
- Eine Transaktion mit normaler Priorität (
CFS other) - Eine Transaktion nach Echtzeitpriorität (
RT-fifo)
- Eine Transaktion mit normaler Priorität (
"S": 9352- 9.352 Transaktionen werden auf derselben CPU synchronisiert.
"R": 0.9352- Gibt das Verhältnis an, in dem Client und Server auf derselben CPU synchronisiert werden.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- Der Durchschnitt (
avg), der schlechteste Fall (wst) und der beste Fall (bst) für alle Transaktionen, die von einem Aufrufer mit normaler Priorität gesendet wurden. Bei zwei Transaktionen ist der Terminmiss, sodass das Erfüllungsverhältnis (meetR) 0,9996 beträgt. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Ähnlich wie
other_ms, aber für vom Kunden ausgeführte Transaktionen mit der Prioritätrt_fifo. Es ist wahrscheinlich (aber nicht zwingend), dassfifo_msein besseres Ergebnis alsother_msliefert, mit niedrigeren Werten füravgundwstund einem höheren Wert fürmeetR. Bei der Hintergrundauslastung kann der Unterschied noch größer sein.
Hinweis:Die Hintergrundlast kann sich auf das Durchsatzergebnis und den other_ms-Tupel im Latenztest auswirken. Nur fifo_ms kann ähnliche Ergebnisse liefern, solange die Hintergrundlast eine niedrigere Priorität als RT-fifo hat.
Paarwerte angeben
Jeder Clientprozess wird mit einem Serverprozess gekoppelt, der dem Client zugewiesen ist. Jedes Paar kann unabhängig auf einer beliebigen CPU geplant werden. Die CPU-Migration sollte jedoch nicht während einer Transaktion erfolgen, solange das SYNC-Flag honor ist.
Das System darf nicht überlastet sein. Eine hohe Latenz bei einem überlasteten System ist zwar zu erwarten, aber die Testergebnisse für ein überlastetes System liefern keine nützlichen Informationen. Verwenden Sie -pair
#cpu-1 (oder mit Vorsicht -pair #cpu), um ein System mit höherem Druck zu testen. Tests mit -pair n und n > #cpu überlasten das System und generieren nutzlose Informationen.
Fristwerte angeben
Nach umfangreichen Tests von Nutzerszenarien (durchführung des Latenztests an einem qualifizierten Produkt) haben wir festgestellt, dass 2,5 ms der Grenzwert sind. Für neue Anwendungen mit höheren Anforderungen (z. B. 1.000 Fotos/Sekunde) ändert sich dieser Termin.
Detaillierte Ausgabe angeben
Wenn Sie die Option -v verwenden, wird eine ausführliche Ausgabe angezeigt. Beispiel:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- Der Dienst-Thread wird mit der Priorität
SCHED_OTHERerstellt und inCPU:1mitpid 8674ausgeführt. - Die erste Transaktion wird dann durch eine
fifo-callergestartet. Um diese Transaktion zu bearbeiten, erhöht der hwbinder die Priorität des Servers (pid: 8674 tid: 8676) auf 99 und kennzeichnet ihn außerdem mit einer vorübergehenden Planungsklasse (???). Der Scheduler fügt den Serverprozess dann inCPU:0ein, um ihn auszuführen, und synchronisiert ihn mit derselben CPU wie den Client. - Der Aufrufer der zweiten Transaktion hat die Priorität
SCHED_OTHER. Der Server stuft sich selbst herab und bedient den Anrufer mit der PrioritätSCHED_OTHER.
Trace für die Fehlerbehebung verwenden
Sie können die Option -trace angeben, um Latenzprobleme zu beheben. Wenn dieser Test verwendet wird, wird die Protokollaufzeichnung durch den Latenztest beendet, sobald eine schlechte Latenz erkannt wird. Beispiel:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Die folgenden Komponenten können sich auf die Latenz auswirken:
- Android-Buildmodus Der Eng-Modus ist in der Regel langsamer als der Userdebug-Modus.
- Framework Wie verwendet der Framework-Dienst
ioctl, um den Binder zu konfigurieren? - Binder-Treiber Unterstützt der Treiber die detaillierte Blockierung? Enthält es alle Leistungsoptimierungs-Patches?
- Kernel-Version Je besser die Echtzeitfähigkeit des Kernels ist, desto besser sind die Ergebnisse.
- Kernel-Konfiguration Enthält die Kernelkonfiguration
DEBUG-Konfigurationen wieDEBUG_PREEMPTundDEBUG_SPIN_LOCK? - Kernel-Scheduler: Verfügt der Kernel über einen energiebewussten Scheduler (EAS) oder einen Scheduler für heterogene Multi-Processing (HMP)? Haben Kerneltreiber (
cpu-freq-Treiber,cpu-idle-Treiber,cpu-hotplugusw.) Auswirkungen auf den Scheduler?