
Android 8.0 incluye pruebas de rendimiento de Binder y hwbinder para la capacidad de procesamiento y la latencia. Si bien existen muchas situaciones para detectar problemas de rendimiento perceptibles, ejecutarlas puede llevar tiempo y los resultados suelen no estar disponibles hasta después de que se integra un sistema. El uso de las pruebas de rendimiento proporcionadas facilita las pruebas durante el desarrollo, detecta problemas graves con anticipación y mejora la experiencia del usuario.
Las pruebas de rendimiento incluyen las siguientes cuatro categorías:
- Capacidad de procesamiento de Binder (disponible en
system/libhwbinder/vts/performance/Benchmark_binder.cpp) - Latencia de Binder (disponible en
frameworks/native/libs/binder/tests/schd-dbg.cpp) - Capacidad de procesamiento de hwbinder (disponible en
system/libhwbinder/vts/performance/Benchmark.cpp) - Latencia de hwbinder (disponible en
system/libhwbinder/vts/performance/Latency.cpp)
Información acerca de Binder y hwbinder
Binder y hwbinder son infraestructuras de comunicación entre procesos (IPC) de Android que comparten el mismo controlador de Linux, pero tienen las siguientes diferencias cualitativas:
| Aspecto | carpeta | hwbinder |
|---|---|---|
| Propósito | Proporciona un esquema de IPC de uso general para el framework | Cómo comunicarse con el hardware |
| Propiedad | Optimizado para el uso del framework de Android | Latencia baja con sobrecarga mínima |
| Cambia la política de programación para primer o segundo plano | Sí | No |
| Pasaje de argumentos | Usa la serialización compatible con el objeto Parcel | Usa búferes de dispersión y evita la sobrecarga para copiar los datos necesarios para la serialización de parcelas. |
| Herencia de prioridad | No | Sí |
Procesos de Binder y hwbinder
Un visualizador de systrace muestra las transacciones de la siguiente manera:
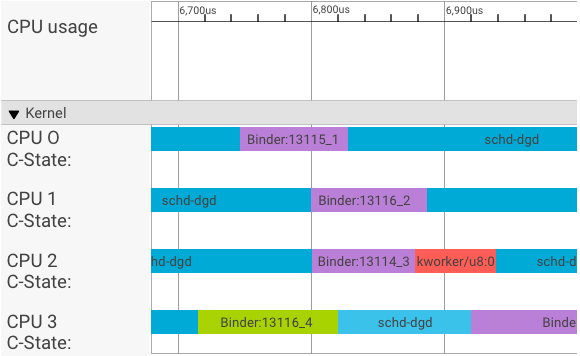
En el ejemplo anterior, ocurre lo siguiente:
- Los cuatro (4) procesos schd-dbg son procesos de cliente.
- Los cuatro (4) procesos de Binder son procesos de servidor (el nombre comienza con Binder y termina con un número de secuencia).
- Un proceso de cliente siempre se vincula con un proceso de servidor, que se dedica a su cliente.
- El kernel programa de forma independiente todos los pares de procesos cliente-servidor de forma simultánea.
En la CPU 1, el kernel del SO ejecuta el cliente para emitir la solicitud. Luego, usa la misma CPU siempre que sea posible para activar un proceso del servidor, controlar la solicitud y volver a cambiar de contexto después de que se complete la solicitud.
Capacidad de procesamiento en comparación con la latencia
En una transacción perfecta, en la que el cliente y el servidor se cambian sin problemas, las pruebas de rendimiento y latencia no producen mensajes muy diferentes. Sin embargo, cuando el kernel del SO controla una solicitud de interrupción (IRQ) del hardware, espera bloqueos o simplemente elige no controlar un mensaje de inmediato, se puede formar una burbuja de latencia.
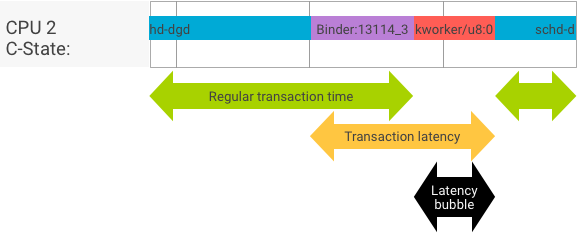
La prueba de rendimiento genera una gran cantidad de transacciones con diferentes tamaños de carga útil, lo que proporciona una buena estimación del tiempo de transacción normal (en los mejores casos) y la capacidad de procesamiento máxima que puede alcanzar el Binder.
En cambio, la prueba de latencia no realiza ninguna acción en la carga útil para minimizar el tiempo de transacción normal. Podemos usar el tiempo de transacción para estimar la sobrecarga de Binder, generar estadísticas para el peor de los casos y calcular la proporción de transacciones cuya latencia cumple con una fecha límite especificada.
Cómo controlar las inversiones de prioridad
Una inversión de prioridades ocurre cuando un subproceso con prioridad más alta espera, de forma lógica, a un subproceso con prioridad más baja. Las aplicaciones en tiempo real (RT) tienen un problema de inversión de prioridad:
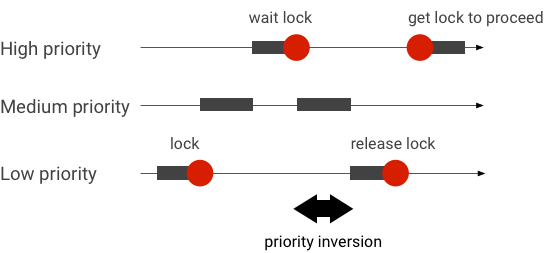
Cuando se usa la programación del programador completamente justo (CFS) de Linux, un subproceso siempre tiene la oportunidad de ejecutarse, incluso cuando otros subprocesos tienen una prioridad más alta. Como resultado, las aplicaciones con programación de CFS controlan la inversión de prioridad como un comportamiento esperado y no como un problema. Sin embargo, en los casos en que el framework de Android necesita programación de RT para garantizar el privilegio de subprocesos de alta prioridad, se debe resolver la inversión de prioridades.
Ejemplo de inversión de prioridad durante una transacción de Binder (otros subprocesos de CFS bloquean lógicamente el subproceso de RT cuando esperan que se atienda un subproceso de Binder):
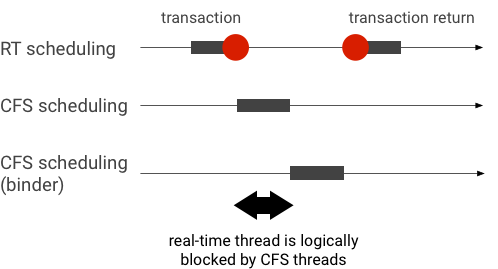
Para evitar bloqueos, puedes usar la herencia de prioridad para derivar temporalmente el subproceso de Binder a un subproceso de RT cuando se atienda una solicitud de un cliente de RT. Ten en cuenta que la programación de RT tiene recursos limitados y se debe usar con cuidado. En un sistema con n CPUs, la cantidad máxima de subprocesos de RT actuales también es n. Es posible que los subprocesos de RT adicionales deban esperar (y, por lo tanto, perder sus plazos) si otras subprocesos de RT ocupan todas las CPUs.
Para resolver todas las posibles inversiones de prioridad, puedes usar la herencia de prioridad para binder y hwbinder. Sin embargo, como Binder se usa ampliamente en todo el sistema, habilitar la herencia de prioridad para las transacciones de Binder podría enviar spam al sistema con más subprocesos de RT de los que puede admitir.
Ejecuta pruebas de capacidad de procesamiento
La prueba de rendimiento se ejecuta en función de la capacidad de procesamiento de transacciones de Binder/hwbinder. En un sistema que no está sobrecargado, las burbujas de latencia son raras y su impacto se puede eliminar, siempre y cuando la cantidad de iteraciones sea lo suficientemente alta.
- La prueba de rendimiento de binder está en
system/libhwbinder/vts/performance/Benchmark_binder.cpp. - La prueba de rendimiento de hwbinder se encuentra en
system/libhwbinder/vts/performance/Benchmark.cpp.
Resultados de la prueba
Ejemplo de resultados de la prueba de rendimiento para transacciones que usan diferentes tamaños de carga útil:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- Tiempo indica la demora de ida y vuelta medida en tiempo real.
- CPU indica el tiempo acumulado cuando las CPUs están programadas para la prueba.
- Iteraciones indica la cantidad de veces que se ejecutó la función de prueba.
Por ejemplo, para una carga útil de 8 bytes, haz lo siguiente:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… la capacidad de procesamiento máxima que puede alcanzar el Binder se calcula de la siguiente manera:
Capacidad de procesamiento MÁXIMA con carga útil de 8 bytes = (8 × 21296)/69974 ≈ 2.423 b/ns ≈ 2.268 Gb/s
Opciones de prueba
Para obtener resultados en .json, ejecuta la prueba con el argumento --benchmark_format=json:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}Ejecuta pruebas de latencia
La prueba de latencia mide el tiempo que tarda el cliente en comenzar a inicializar la transacción, cambiar al proceso del servidor para su control y recibir el resultado. La prueba también busca comportamientos conocidos de programadores incorrectos que pueden afectar negativamente la latencia de las transacciones, como un programador que no admite la herencia de prioridad ni respeta la marca de sincronización.
- La prueba de latencia de Binder está en
frameworks/native/libs/binder/tests/schd-dbg.cpp. - La prueba de latencia de hwbinder se encuentra en
system/libhwbinder/vts/performance/Latency.cpp.
Resultados de la prueba
Los resultados (en .json) muestran estadísticas de la latencia promedio, la mejor y la peor, y la cantidad de plazos perdidos.
Opciones de prueba
Las pruebas de latencia tienen las siguientes opciones:
| Comando | Descripción |
|---|---|
-i value |
Especifica la cantidad de iteraciones. |
-pair value |
Especifica la cantidad de pares de procesos. |
-deadline_us 2500 |
Especifica la fecha límite en EE.UU. |
-v |
Obtén un resultado detallado (depuración). |
-trace |
Detener el seguimiento cuando se alcanza una fecha límite |
En las siguientes secciones, se detalla cada opción, se describe el uso y se proporcionan resultados de ejemplo.
Especifica las iteraciones
Ejemplo con una gran cantidad de iteraciones y salida detallada inhabilitada:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}Estos resultados de la prueba muestran lo siguiente:
"pair":3- Crea un par de cliente y servidor.
"iterations": 5000- Incluye 5,000 iteraciones.
"deadline_us":2500- El plazo es de 2500 us (2.5 ms); se espera que la mayoría de las transacciones cumplan con este valor.
"I": 10000- Una sola iteración de prueba incluye dos (2) transacciones:
- Una transacción por prioridad normal (
CFS other) - Una transacción por prioridad en tiempo real (
RT-fifo)
- Una transacción por prioridad normal (
"S": 9352- 9352 de las transacciones se sincronizan en la misma CPU.
"R": 0.9352- Indica la proporción a la que se sincronizan el cliente y el servidor en la misma CPU.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- El caso promedio (
avg), el peor (wst) y el mejor (bst) para todas las transacciones emitidas por un llamador de prioridad normal. Dos transaccionesmissla fecha límite, por lo que la proporción de cumplimiento (meetR) es 0.9996. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}- Es similar a
other_ms, pero para las transacciones emitidas por el cliente con prioridadrt_fifo. Es probable (pero no obligatorio) quefifo_mstenga un mejor resultado queother_ms, con valores más bajos deavgywst, y unmeetRmás alto (la diferencia puede ser aún más significativa con la carga en segundo plano).
Nota: La carga en segundo plano puede afectar el resultado de la capacidad de procesamiento y la tupla other_ms en la prueba de latencia. Solo fifo_ms puede mostrar resultados similares, siempre y cuando la carga en segundo plano tenga una prioridad más baja que RT-fifo.
Especifica los valores de los pares
Cada proceso de cliente se vincula con un proceso de servidor dedicado al cliente, y cada par se puede programar de forma independiente en cualquier CPU. Sin embargo, la migración de la CPU no debe ocurrir durante una transacción, siempre que la marca SYNC sea honor.
Asegúrate de que el sistema no esté sobrecargado. Si bien se espera una latencia alta en un sistema sobrecargado, los resultados de las pruebas de un sistema sobrecargado no proporcionan información útil. Para probar un sistema con una presión más alta, usa -pair
#cpu-1 (o -pair #cpu con precaución). Las pruebas con -pair n con n > #cpu sobrecargan el sistema y generan información inútil.
Especifica los valores de la fecha límite
Después de realizar pruebas exhaustivas de situaciones de los usuarios (ejecutar la prueba de latencia en un producto calificado), determinamos que 2.5 ms es el plazo que se debe cumplir. Para las aplicaciones nuevas con requisitos más altos (como 1,000 fotos por segundo), este valor de fecha límite cambiará.
Especifica un resultado detallado
Si usas la opción -v, se mostrará un resultado detallado. Ejemplo:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- El subproceso de servicio se crea con una prioridad
SCHED_OTHERy se ejecuta enCPU:1conpid 8674. - Luego, un
fifo-callerinicia la primera transacción. Para atender esta transacción, hwbinder actualiza la prioridad del servidor (pid: 8674 tid: 8676) a 99 y también lo marca con una clase de programación transitoria (impresa como???). Luego, el programador coloca el proceso del servidor enCPU:0para que se ejecute y lo sincroniza con la misma CPU con su cliente. - El llamador de la segunda transacción tiene una prioridad
SCHED_OTHER. El servidor se cambia a una versión inferior y atiende al llamador con prioridadSCHED_OTHER.
Usa el seguimiento para depurar
Puedes especificar la opción -trace para depurar problemas de latencia. Cuando se usa, la prueba de latencia detiene la grabación del registro de seguimiento en el momento en que se detecta una latencia deficiente. Ejemplo:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
Los siguientes componentes pueden afectar la latencia:
- Modo de compilación de Android. El modo Eng suele ser más lento que el modo userdebug.
- Framework: ¿Cómo usa el servicio del framework
ioctlpara configurar el Binder? - Controlador de Binder. ¿El controlador admite el bloqueo detallado? ¿Incluye todos los parches de optimización del rendimiento?
- Versión del kernel: Cuanto mejor sea la capacidad en tiempo real del kernel, mejores serán los resultados.
- Configuración del kernel. ¿La configuración del kernel contiene configuraciones de
DEBUG, comoDEBUG_PREEMPTyDEBUG_SPIN_LOCK? - Programador de kernel. ¿El kernel tiene un planificador consciente de la energía (EAS) o un planificador de procesamiento múltiple heterogéneo (HMP)? ¿Algunos controladores del kernel (controlador
cpu-freq, controladorcpu-idle,cpu-hotplug, etcétera) afectan al programador?