
Pour prendre en charge un tableau de bord d'intégration continue évolutif, performant et flexible, le backend du tableau de bord VTS doit être soigneusement conçu en s'appuyant sur une bonne compréhension des fonctionnalités de la base de données. Google Cloud Datastore est une base de données NoSQL qui offre des garanties ACID transactionnelles et une cohérence finale, ainsi qu'une cohérence forte au sein des groupes d'entités. Cependant, la structure est très différente des bases de données SQL (et même de Cloud Bigtable) : au lieu de tables, de lignes et de cellules, il existe des types, des entités et des propriétés.
Les sections suivantes décrivent la structure de données et les modèles de requêtes permettant de créer un backend efficace pour le service Web VTS Dashboard.
Entités
Les entités suivantes stockent les résumés et les ressources des exécutions de test VTS:
- Entité de test Stocke les métadonnées sur les exécutions de test d'un test particulier. Sa clé est le nom du test, et ses propriétés incluent le nombre d'échecs, le nombre de réussites et la liste des cas de test qui ne fonctionnent pas à partir du moment où les tâches d'alerte le mettent à jour.
- Entité d'exécution du test Contient les métadonnées des exécutions d'un test particulier. Il doit stocker les codes temporels de début et de fin du test, l'ID de build du test, le nombre de cas de test réussis et échoués, le type d'exécution (par exemple, pré-soumission, post-soumission ou local), une liste de liens de journal, le nom de la machine hôte et les totaux récapitulatifs de couverture.
- Entité d'informations sur l'appareil Contient des informations sur les appareils utilisés lors de l'exécution du test. Il inclut l'ID de build de l'appareil, le nom du produit, la cible de compilation, la branche et les informations ABI. Il est stocké séparément de l'entité d'exécution de test pour prendre en charge les exécutions de test multi-appareils de manière un à plusieurs.
- Profilage de l'entité d'exécution du point. Résume les données collectées pour un point de profilage spécifique lors d'une exécution de test. Il décrit les libellés des axes, le nom du point de profilage, les valeurs, le type et le mode de régression des données de profilage.
- Entité de couverture Décrit les données de couverture collectées pour un fichier. Il contient les informations du projet Git, le chemin d'accès au fichier et la liste des nombres de couverture par ligne dans le fichier source.
- Entité d'exécution du scénario de test Décrit le résultat d'un scénario de test particulier à partir d'une exécution de test, y compris le nom du scénario de test et son résultat.
- Entité "Favoris de l'utilisateur" Chaque abonnement utilisateur peut être représenté dans une entité contenant une référence au test et l'ID utilisateur généré à partir du service utilisateur App Engine. Cela permet d'effectuer des requêtes bidirectionnelles efficaces (c'est-à-dire pour tous les utilisateurs abonnés à un test et pour tous les tests ajoutés aux favoris par un utilisateur).
Regroupement d'entités
Chaque module de test représente la racine d'un groupe d'entités. Les entités d'exécution de test sont à la fois enfants de ce groupe et parents des entités d'appareil, des entités de point de profilage et des entités de couverture pertinentes pour l'ancêtre respectif du test et de l'exécution de test.
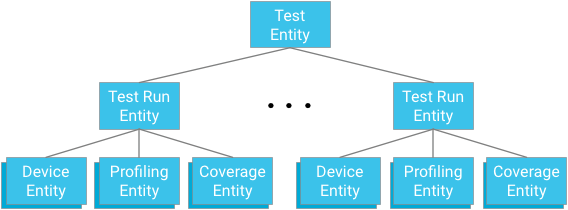
Important:Lorsque vous concevez des relations d'ascendance, vous devez équilibrer le besoin de fournir des mécanismes de requête efficaces et cohérents avec les limites imposées par la base de données.
Avantages
L'exigence de cohérence garantit que les futures opérations ne verront pas les effets d'une transaction tant qu'elle n'a pas été validée, et que les transactions passées sont visibles par les opérations actuelles. Dans Cloud Datastore, le regroupement d'entités crée des îlots de cohérence forte en lecture et en écriture au sein du groupe, qui, dans ce cas, correspond à l'ensemble des exécutions de test et des données associées à un module de test. Cela présente les avantages suivants:
- Les lectures et les mises à jour de l'état du module de test par les tâches d'alerte peuvent être traitées comme atomiques.
- Affichage cohérent garanti des résultats des scénarios de test dans les modules de test
- Requêtes plus rapides dans les arbres généalogiques
Limites
Il est déconseillé d'écrire dans un groupe d'entités à une fréquence supérieure à une entité par seconde, car certaines écritures peuvent être refusées. Tant que les tâches d'alerte et l'importation ne se produisent pas à un débit supérieur à une écriture par seconde, la structure est solide et garantit une cohérence élevée.
En fin de compte, la limite d'une écriture par module de test par seconde est raisonnable, car les exécutions de test prennent généralement au moins une minute, y compris les frais généraux du framework VTS. À moins qu'un test ne soit exécuté simultanément sur plus de 60 hôtes différents, il ne peut pas y avoir de goulot d'étranglement d'écriture. Cela devient encore plus improbable étant donné que chaque module fait partie d'un plan de test qui dure souvent plus d'une heure. Les anomalies peuvent être facilement gérées si les hôtes exécutent les tests en même temps, ce qui provoque de courtes rafales d'écritures sur les mêmes hôtes (par exemple, en détectant les erreurs d'écriture et en réessayant).
Remarques concernant le scaling
Une exécution de test n'a pas nécessairement besoin d'avoir le test comme parent (par exemple, il peut prendre une autre clé et avoir le nom du test, l'heure de début du test comme propriétés). Toutefois, cela échangera une cohérence forte contre une cohérence éventuelle. Par exemple, la tâche d'alerte peut ne pas afficher un instantané mutuellement cohérent des exécutions de test les plus récentes dans un module de test, ce qui signifie que l'état global peut ne pas représenter de manière totalement précise la séquence d'exécutions de test. Cela peut également avoir un impact sur l'affichage des exécutions de test dans un seul module de test, qui ne sera pas nécessairement un instantané cohérent de la séquence d'exécution. À terme, l'instantané sera cohérent, mais il n'est pas garanti que les données les plus récentes le soient également.
Scénarios de test
Les tests volumineux avec de nombreux cas de test peuvent également constituer un goulot d'étranglement. Les deux contraintes opérationnelles sont le débit d'écriture maximal d'un groupe d'entités d'une seconde, ainsi qu'une taille de transaction maximale de 500 entités.
Une approche consiste à spécifier un cas de test qui a une exécution de test comme ancêtre (comme le stockage des données de couverture, des données de profilage et des informations sur l'appareil):
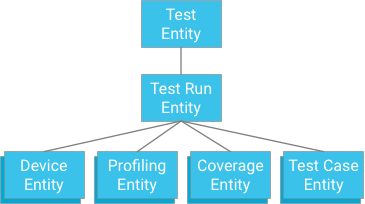
Bien que cette approche offre l'atomicité et la cohérence, elle impose des limites strictes aux tests: si une transaction est limitée à 500 entités, un test ne peut pas comporter plus de 498 cas de test (en supposant qu'il n'y ait pas de données de couverture ni de profilage). Si un test dépasse cette valeur, une seule transaction ne peut pas écrire tous les résultats du scénario de test en même temps. Diviser les scénarios de test en transactions distinctes peut dépasser le débit d'écriture maximal du groupe d'entités, qui est d'une itération par seconde. Cette solution n'est pas recommandée, car elle ne s'adapte pas bien sans sacrifier les performances.
Toutefois, au lieu de stocker les résultats des scénarios de test en tant qu'enfants de l'exécution de test, les scénarios de test peuvent être stockés indépendamment et leurs clés fournies à l'exécution de test (une exécution de test contient une liste d'identifiants de ses entités de scénarios de test):
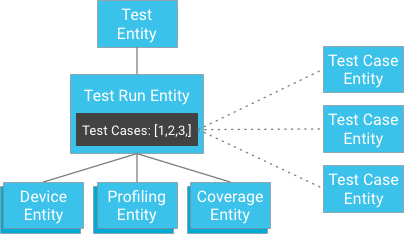
À première vue, cela peut sembler enfreindre la garantie de cohérence forte. Toutefois, si le client dispose d'une entité d'exécution de test et d'une liste d'identifiants de cas de test, il n'a pas besoin de créer une requête. Il peut plutôt obtenir directement les cas de test par leurs identifiants, ce qui est toujours garanti pour être cohérent. Cette approche réduit considérablement la contrainte liée au nombre de scénarios de test qu'une exécution de test peut avoir, tout en assurant une cohérence forte sans menacer d'écriture excessive au sein d'un groupe d'entités.
Modèles d'accès aux données
Le tableau de bord VTS utilise les modèles d'accès aux données suivants:
- Favoris de l'utilisateur Vous pouvez effectuer des requêtes à l'aide d'un filtre d'égalité sur les entités de favoris utilisateur ayant l'objet utilisateur App Engine en question comme propriété.
- Fiches de test Requête simple sur les entités de test. Pour réduire la bande passante nécessaire à l'affichage de la page d'accueil, une projection peut être utilisée sur les nombres de réussites et d'échecs afin d'omettre la liste potentiellement longue des ID de cas de test ayant échoué et d'autres métadonnées utilisées par les tâches d'alerte.
- Exécutions de test L'interrogation des entités de test nécessite un tri sur la clé (code temporel) et un filtrage possible sur les propriétés de test, telles que l'ID de compilation, le nombre de réussites, etc. En effectuant une requête d'ancêtre avec une clé d'entité de test, la lecture est fortement cohérente. À ce stade, tous les résultats du cas de test peuvent être récupérés à l'aide de la liste des ID stockés dans une propriété d'exécution de test. De plus, le résultat est fortement cohérent en raison de la nature des opérations de récupération de Datastore.
- Données de profilage et de couverture Vous pouvez interroger des données de profilage ou de couverture associées à un test sans récupérer d'autres données d'exécution de test (telles que d'autres données de profilage/de couverture, des données de cas de test, etc.). Une requête aïeule utilisant les clés d'entité de test et d'exécution de test permet de récupérer tous les points de profilage enregistrés lors de l'exécution de test. En filtrant également sur le nom ou le nom de fichier du point de profilage, une seule entité de profilage ou de couverture peut être récupérée. Par nature, les requêtes ascendantes sont fortement cohérentes.
Pour en savoir plus sur l'interface utilisateur et obtenir des captures d'écran de ces modèles de données en action, consultez la section Interface utilisateur du tableau de bord VTS.