
Aby zapewnić skalowalność, wydajność i elastyczność panelu ciągłej integracji, backend panelu VTS musi być zaprojektowany z uwzględnieniem szczegółowej znajomości funkcji bazy danych. Google Cloud Datastore to baza danych NoSQL, która zapewnia transakcyjne gwarancje ACID oraz spójność ostatecznie silną i ostatecznie słabą w ramach grup elementów. Struktura jest jednak bardzo różna od baz danych SQL (a nawet Bigtable w chmurze). Zamiast tabel, wierszy i komórek mamy rodzaje, elementy i właściwości.
W kolejnych sekcjach opisano strukturę danych i wzorce zapytań, które pomogą Ci stworzyć skuteczne zaplecze dla usługi internetowej Panelu VTS.
Jednostki
Podsumowania i zasoby z testów VTS są przechowywane w tych typach jednostek:
- Test Entity. Przechowuje metadane dotyczące uruchomień testu konkretnego testu. Jego kluczem jest nazwa testu, a właściwości obejmują liczbę niepowodzeń, liczbę przypadków, w których test się powiódł, oraz listę przypadków testowych, które nie przeszły, od momentu ich zaktualizowania przez zadania alertów.
- Test Run Entity (Testowanie jednostki Run). Zawiera metadane z wyników wykonania konkretnego testu. Musi zawierać sygnatury czasowe rozpoczęcia i zakończenia testu, identyfikator kompilacji testu, liczbę przypadków testowych z pozytywnym i ujemnym wynikiem, typ uruchomienia (np. przed przesłaniem, po przesłaniu lub lokalnie), listę linków do dzienników, nazwę komputera hosta oraz podsumowanie pokrycia.
- Element informacji o urządzeniu. Zawiera szczegółowe informacje o urządzeniach użytych podczas testu. Zawiera identyfikator kompilacji urządzenia, nazwę produktu, informacje o docelniku kompilacji, gałęzi i ABI. Jest on przechowywany oddzielnie od elementu testu, aby umożliwić testowanie na wielu urządzeniach w schemacie jeden-do-wielu.
- Punkt pomiarowy w ramach elementu Profilowanie. Podsumowanie danych zebranych w przypadku konkretnego punktu profilowania w ramach wykonania testu. Zawiera etykiety osi, nazwę punktu profilowania, wartości, typ i tryb regresji danych profilowania.
- Jednostka pokrycia. Opisuje dane dotyczące zasięgu zebrane dla danego pliku. Zawiera informacje o projekcie Git, ścieżkę do pliku i listę liczby pokrycia na wiersz w pliku źródłowym.
- Test Case Run Entity (Jednostka testu działania przypadku). Opisuje wynik konkretnego przypadku testowego z określonego uruchomienia testu, w tym nazwę przypadku testowego i jego wynik.
- Jednostka Ulubione użytkownika. Każda subskrypcja użytkownika może być reprezentowana przez element zawierający odwołanie do testu i identyfikator użytkownika wygenerowany z usługi użytkownika App Engine. Umożliwia to wydajne wykonywanie zapytań dwukierunkowych (czyli dotyczących wszystkich użytkowników zapisanych na test i wszystkich testów oznaczonych jako ulubione przez użytkownika).
Grupowanie elementów
Każdy moduł testowy reprezentuje element rdzeniowy grupy elementów. Elementy testu są zarówno elementami podrzędnymi tej grupy, jak i elementami nadrzędnymi dla elementów urządzenia, punktów profilowania i elementów pokrycia, które są istotne dla danego testu i danego uruchomienia testu.
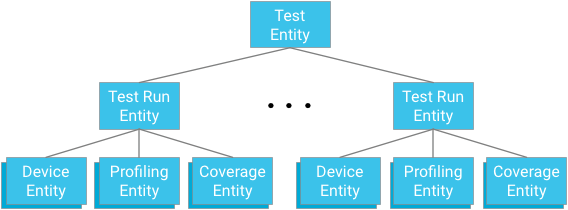
Ważna informacja: podczas projektowania relacji pokrewieństwa musisz znaleźć równowagę między potrzebą zapewnienia skutecznych i spójnych mechanizmów zapytań a ograniczeniami narzucanymi przez bazę danych.
Zalety
Wymóg spójności zapewnia, że przyszłe operacje nie będą uwzględniać skutków transakcji, dopóki nie zostanie ona zatwierdzona, oraz że transakcje z przeszłości będą widoczne dla bieżących operacji. W Cloud Datastore grupowanie encji tworzy w grupie wyspy spójności odczytu i zapisu, które w tym przypadku obejmują wszystkie testy i dane związane z modułem testowym. Daje to następujące korzyści:
- Czytania i aktualizacje stanu modułu testowego przez zadania alertów mogą być traktowane jako atomowe
- Gwarantowane spójne wyświetlanie wyników przypadków testowych w modułach testowych
- Szybsze wykonywanie zapytań w drzewach genealogicznych
Ograniczenia
Nie zalecamy zapisywania w grupie elementów z częstotliwością większą niż 1 element na sekundę, ponieważ niektóre zapisy mogą zostać odrzucone. Dopóki zadania alertów i przesyłanie nie odbywają się z szybkością większą niż 1 zapisu na sekundę, struktura jest stabilna i gwarantuje dużą spójność.
Ostatecznie ograniczenie do 1 zapisu na moduł testu na sekundę jest rozsądne, ponieważ testy zwykle trwają co najmniej minutę, wliczając czas potrzebny na obsługę nadmiarowości w ramach VTS. O ile test nie jest stale wykonywany jednocześnie na więcej niż 60 różnych hostach, nie może wystąpić wąskie gardło związane z zapisywaniem. Jest to jeszcze mniej prawdopodobne, biorąc pod uwagę, że każdy moduł jest częścią planu testów, który często trwa dłużej niż godzinę. Anomalie można łatwo usunąć, jeśli hosty uruchamiają testy w tym samym czasie, powodując krótkie serie zapisów na tych samych hostach (np. przez wykrywanie błędów zapisu i próbę ponownego zapisu).
Uwagi dotyczące skalowania
Uruchomienie testu nie musi mieć testu jako elementu nadrzędnego (np.może mieć inny klucz i nazwę testu oraz czas rozpoczęcia testu jako właściwości). Spowoduje to jednak zastąpienie spójności ścisłej spójnością warunkową. Na przykład zadanie alertu może nie widzieć spójnego zrzutu ekranu z najnowszymi testami w module testowym, co oznacza, że stan globalny może nie odzwierciedlać w pełni sekwencji testów. Może to też wpływać na wyświetlanie przebiegów testów w ramach pojedynczego modułu testu, który nie musi być spójnym zbiorem sekwencji przebiegu. Ostatecznie migawka będzie spójna, ale nie ma gwarancji, że będzie zawierać najnowsze dane.
Elementy testowania
Innym potencjalnym wąskim gardłem są duże testy z wiele testami. Dwie ograniczenia operacyjne to maksymalna przepustowość zapisu w grupie elementów wynosząca 1 na sekundę oraz maksymalny rozmiar transakcji wynoszący 500 elementów.
Jednym z podejść jest określenie przypadku testowego, który ma uruchomiony test jako element nadrzędny (podobnie jak dane dotyczące zasięgu, dane do profilowania i informacje o urządzeniu):
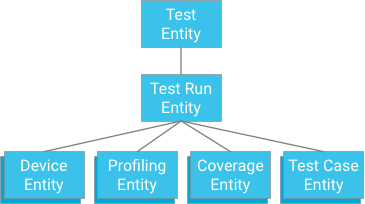
Chociaż takie podejście zapewnia spójność i jednolitość, nakłada na testy silne ograniczenia: jeśli transakcja jest ograniczona do 500 podmiotów, test może zawierać maksymalnie 498 przypadków testowych (przy założeniu, że nie ma danych dotyczących pokrycia ani profilowania). Jeśli test przekroczy tę wartość, pojedyncza transakcja nie będzie mogła zapisać wszystkich wyników testu naraz, a podzielanie testów na oddzielne transakcje może spowodować przekroczenie maksymalnej przepustowości zapisu grupy elementów wynoszącej jedną iterację na sekundę. To rozwiązanie nie skaluje się dobrze bez uszczerbku na wydajność, dlatego nie jest zalecane.
Zamiast jednak przechowywać wyniki testu jako podrzędne testu, możesz przechowywać testy niezależnie i przekazywać ich klucze do testu (test zawiera listę identyfikatorów jego elementów):
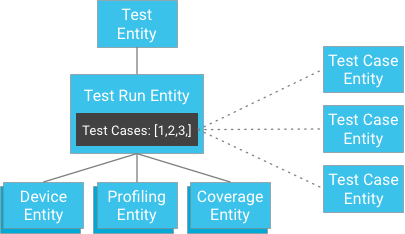
Na pierwszy rzut oka może się wydawać, że narusza to zasadę silnej spójności. Jeśli jednak klient ma element testu i listę identyfikatorów przypadków testowych, nie musi tworzyć zapytania. Może zamiast tego bezpośrednio pobrać przypadki testowe według ich identyfikatorów, co zawsze gwarantuje spójność. Dzięki temu podejściu można znacznie ograniczyć liczbę przypadków testowych, które mogą wystąpić podczas testu, a jednocześnie uzyskać dużą spójność bez ryzyka nadmiernego zapisywania w grupie elementów.
Wzorce dostępu do danych
Panel VTS korzysta z tych wzorów dostępu do danych:
- Ulubione użytkownika. Można je wyszukiwać, używając filtra równości w elementach Ulubione użytkownika, które mają obiekt Użytkownik App Engine jako właściwość.
- Testowanie strony. Proste zapytanie dotyczące testowych jednostek. Aby zmniejszyć przepustowość potrzebną do renderowania strony głównej, można zastosować projekcję zliczania przypadków powodzenia i niepowodzenia, aby pominąć potencjalnie długą listę identyfikatorów nieudanych testów i inne metadane używane przez zadania dotyczące alertów.
- Uruchomienia testowe. Aby zapytać o podmioty testu, musisz je posortować według klucza (sygnatura czasowa) i możliwie odfiltrować według właściwości testu, takich jak identyfikator kompilacji, liczba przejść itp. Wykonując zapytanie o elementy przodka za pomocą klucza elementu testu, uzyskujesz spójne dane. W tym momencie wszystkie wyniki testu można pobrać, korzystając z listy identyfikatorów przechowywanych w właściwości testu. Z charakteru operacji pobierania w danych zbiór danych wynik będzie też w pełni spójny.
- Dane dotyczące profilowania i zasięgu. Zapytania o dane związane z testem, np. dane dotyczące profilowania lub pokrycia, można wysyłać bez pobierania innych danych z testu (np. innych danych o profilowaniu lub pokryciu, danych testów itp.). Zapytanie nadrzędne z kluczami testu i testu wykonania wyodrębni wszystkie punkty profilowania zarejestrowane podczas wykonania testu. Filtrując według nazwy punktu profilowania lub nazwy pliku, można wyodrębnić pojedynczy element profilowania lub element pokrycia. Z racji charakteru zapytań dotyczących elementu nadrzędnego ta operacja jest bardzo spójna.
Szczegółowe informacje o interfejsie użytkownika i zrzuty ekranu pokazujące działanie tych wzorów danych znajdziesz w artykule Interfejs panelu VTS.