
Android 8.0 में, थ्रूपुट और रिस्पॉन्स में लगने वाले समय के लिए, बाइंडर और hwbinder की परफ़ॉर्मेंस की जांच शामिल है. परफ़ॉर्मेंस से जुड़ी समस्याओं का पता लगाने के लिए कई तरीके मौजूद हैं. हालांकि, इन तरीकों को आज़माने में काफ़ी समय लग सकता है. साथ ही, सिस्टम के इंटिग्रेट होने तक नतीजे अक्सर उपलब्ध नहीं होते. परफ़ॉर्मेंस की जांच करने के लिए उपलब्ध टूल का इस्तेमाल करने से, डेवलपमेंट के दौरान जांच करना आसान हो जाता है. साथ ही, गंभीर समस्याओं का पता पहले ही चल जाता है और उपयोगकर्ता अनुभव को बेहतर बनाया जा सकता है.
परफ़ॉर्मेंस की जांच करने की सुविधा में ये चार कैटगरी शामिल हैं:
- बाइंडर थ्रूपुट (
system/libhwbinder/vts/performance/Benchmark_binder.cppमें उपलब्ध है) - बाइंडर के इंतज़ार का समय (
frameworks/native/libs/binder/tests/schd-dbg.cppमें उपलब्ध है) - hwbinder थ्रूपुट (
system/libhwbinder/vts/performance/Benchmark.cppमें उपलब्ध है) - hwbinder के इंतज़ार का समय (
system/libhwbinder/vts/performance/Latency.cppमें उपलब्ध है)
binder और hwbinder के बारे में जानकारी
Binder और hwbinder, Android इंटर-प्रोसेस कम्यूनिकेशन (आईपीसी) इन्फ़्रास्ट्रक्चर हैं. ये एक ही Linux ड्राइवर का इस्तेमाल करते हैं. हालांकि, इनमें ये अंतर हैं:
| पक्ष | बाइंडर | hwbinder |
|---|---|---|
| मकसद | फ़्रेमवर्क के लिए, सामान्य तौर पर इस्तेमाल होने वाली IPC स्कीम उपलब्ध कराएं | हार्डवेयर के साथ इंटरैक्ट करना |
| प्रॉपर्टी | Android फ़्रेमवर्क के इस्तेमाल के लिए ऑप्टिमाइज़ किया गया | कम से कम ओवरहेड और इंतज़ार का कम समय |
| फ़ोरग्राउंड/बैकग्राउंड के लिए शेड्यूलिंग की नीति बदलना | हां | नहीं |
| आर्ग्युमेंट पास करना | Parcel ऑब्जेक्ट के साथ काम करने वाले सीरियलाइज़ेशन का इस्तेमाल करता है | स्कैटर बफ़र का इस्तेमाल करता है और पार्सल को सीरियलाइज़ करने के लिए ज़रूरी डेटा को कॉपी करने से जुड़े ओवरहेड से बचता है |
| प्राथमिकता इनहेरिटेंस | नहीं | हां |
Binder और hwbinder प्रोसेस
systrace विज़ुअलाइज़र, ट्रांज़ैक्शन को इस तरह दिखाता है:
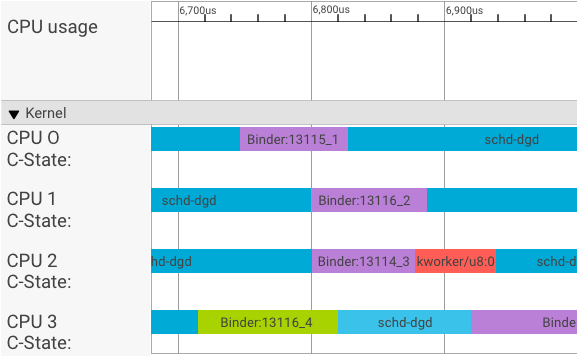
ऊपर दिए गए उदाहरण में:
- चार (4) schd-dbg प्रोसेस, क्लाइंट प्रोसेस हैं.
- चार (4) बाइंडर प्रोसेस, सर्वर प्रोसेस होती हैं. इनका नाम बाइंडर से शुरू होता है और सीक्वेंस नंबर पर खत्म होता है.
- क्लाइंट प्रोसेस को हमेशा किसी सर्वर प्रोसेस के साथ जोड़ा जाता है, जो अपने क्लाइंट के लिए खास तौर पर बनाई गई होती है.
- सभी क्लाइंट-सर्वर प्रोसेस पेयर को, कर्नेल के ज़रिए एक साथ अलग-अलग शेड्यूल किया जाता है.
सीपीयू 1 में, अनुरोध जारी करने के लिए ओएस कर्नेल, क्लाइंट को चलाता है. इसके बाद, जब भी संभव हो, वह उसी सीपीयू का इस्तेमाल करता है, ताकि सर्वर प्रोसेस को चालू किया जा सके, अनुरोध को मैनेज किया जा सके, और अनुरोध पूरा होने के बाद, कॉन्टेक्स्ट स्विच किया जा सके.
थ्रूपुट बनाम इंतज़ार का समय
किसी सही लेन-देन में, क्लाइंट और सर्वर प्रोसेस के बीच आसानी से स्विच होने पर, थ्रुपुट और इंतज़ार का समय जांचने वाले टेस्ट से काफ़ी अलग मैसेज नहीं मिलते. हालांकि, जब ओएस कर्नेल, हार्डवेयर से मिलने वाले इंटरप्ट रिक्वेस्ट (आईआरक्यू) को मैनेज कर रहा हो, लॉक का इंतज़ार कर रहा हो या किसी मैसेज को तुरंत मैनेज न कर रहा हो, तो इंतज़ार का समय बढ़ सकता है.
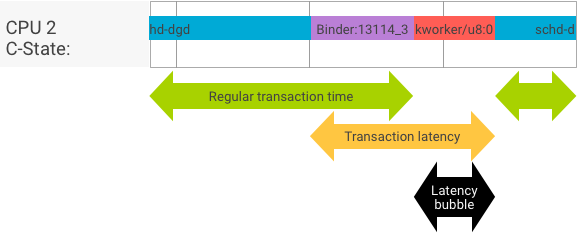
थ्रुपुट टेस्ट, अलग-अलग पेलोड साइज़ के साथ बड़ी संख्या में लेन-देन जनरेट करता है. इससे, सामान्य लेन-देन के समय (सबसे अच्छी स्थिति में) और बाइंडर के ज़रिए हासिल किए जा सकने वाले ज़्यादा से ज़्यादा थ्रुपुट का अच्छा अनुमान मिलता है.
इसके उलट, इंतज़ार का समय जांचने वाला टेस्ट, पेलोड पर कोई कार्रवाई नहीं करता, ताकि सामान्य लेन-देन का समय कम हो सके. हम लेन-देन में लगे समय का इस्तेमाल, बाइंडर के ओवरहेड का अनुमान लगाने, सबसे खराब स्थिति के लिए आंकड़े बनाने, और उन लेन-देन के अनुपात का हिसाब लगाने के लिए कर सकते हैं जिनकी देरी तय समयसीमा के अंदर होती है.
प्राथमिकता के उलट होने की समस्या को हल करना
प्राथमिकता में बदलाव तब होता है, जब ज़्यादा प्राथमिकता वाली थ्रेड, कम प्राथमिकता वाली थ्रेड के लिए इंतज़ार कर रही हो. रीयल-टाइम (आरटी) ऐप्लिकेशन में प्राथमिकता बदलने की समस्या होती है:

Linux Completely Fair Scheduler (CFS) शेड्यूलिंग का इस्तेमाल करने पर, किसी थ्रेड को हमेशा रन करने का मौका मिलता है. भले ही, अन्य थ्रेड की प्राथमिकता ज़्यादा हो. इस वजह से, सीएफ़एस शेड्यूलिंग वाले ऐप्लिकेशन, प्राथमिकता के उलट होने की समस्या को समस्या के तौर पर नहीं, बल्कि उम्मीद के मुताबिक व्यवहार के तौर पर मैनेज करते हैं. हालांकि, जिन मामलों में Android फ़्रेमवर्क को ज़्यादा प्राथमिकता वाली थ्रेड का ऐक्सेस देने के लिए, आरटी शेड्यूलिंग की ज़रूरत होती है उनमें प्राथमिकता में बदलाव की समस्या को ठीक करना ज़रूरी है.
बाइंडर ट्रांज़ैक्शन के दौरान प्राथमिकता बदलने का उदाहरण (RT थ्रेड को, बाइंडर थ्रेड के काम करने का इंतज़ार करते समय, सीएफ़एस के अन्य थ्रेड लॉजिकली ब्लॉक करते हैं):
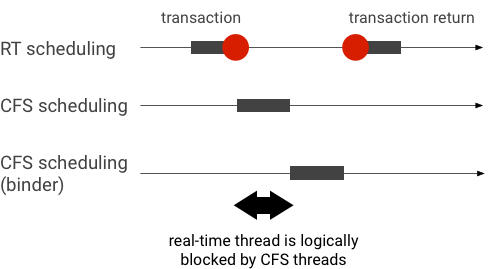
रुकावटों से बचने के लिए, प्राथमिकता के इनहेरिटेंस का इस्तेमाल करके, Binder थ्रेड को कुछ समय के लिए आरटी थ्रेड में बदला जा सकता है. ऐसा तब किया जाता है, जब यह आरटी क्लाइंट से मिले अनुरोध को पूरा करता है. ध्यान रखें कि आरटी शेड्यूलिंग के लिए सीमित संसाधन होते हैं और इसका इस्तेमाल सावधानी से किया जाना चाहिए. n सीपीयू वाले सिस्टम में, मौजूदा आरटी थ्रेड की ज़्यादा से ज़्यादा संख्या भी n होती है. अगर सभी सीपीयू, अन्य आरटी थ्रेड के पास हैं, तो हो सकता है कि अतिरिक्त आरटी थ्रेड को इंतज़ार करना पड़े और इसलिए, वे तय समयसीमा से ज़्यादा समय तक चलें.
प्राथमिकता के सभी संभावित उलटावों को हल करने के लिए, binder और hwbinder, दोनों के लिए प्राथमिकता के इनहेरिटेंस का इस्तेमाल किया जा सकता है. हालांकि, पूरे सिस्टम में बाइंडर का ज़्यादा इस्तेमाल किया जाता है. इसलिए, बाइंडर लेन-देन के लिए प्राथमिकता इनहेरिटेंस की सुविधा चालू करने पर, सिस्टम में ज़्यादा आरटी थ्रेड हो सकते हैं.
थ्रूपुट टेस्ट चलाना
थ्रूपुट टेस्ट, बाइंडर/hwbinder लेन-देन के थ्रूपुट के हिसाब से चलाया जाता है. किसी ऐसे सिस्टम में, जहां ज़्यादा लोड नहीं है, इंतज़ार का समय कम होता है. साथ ही, जब तक दोहराए जाने वाले अनुरोधों की संख्या ज़्यादा होती है, तब तक इंतज़ार के समय पर होने वाले असर को कम किया जा सकता है.
- बाइंडर का थ्रुपुट टेस्ट,
system/libhwbinder/vts/performance/Benchmark_binder.cppमें है. - hwbinder का थ्रूपुट टेस्ट,
system/libhwbinder/vts/performance/Benchmark.cppमें है.
परीक्षण के नतीजे
अलग-अलग पेलोड साइज़ का इस्तेमाल करने वाले लेन-देन के लिए, थ्रुपुट की जांच के नतीजों का उदाहरण:
Benchmark Time CPU Iterations --------------------------------------------------------------------- BM_sendVec_binderize/4 70302 ns 32820 ns 21054 BM_sendVec_binderize/8 69974 ns 32700 ns 21296 BM_sendVec_binderize/16 70079 ns 32750 ns 21365 BM_sendVec_binderize/32 69907 ns 32686 ns 21310 BM_sendVec_binderize/64 70338 ns 32810 ns 21398 BM_sendVec_binderize/128 70012 ns 32768 ns 21377 BM_sendVec_binderize/256 69836 ns 32740 ns 21329 BM_sendVec_binderize/512 69986 ns 32830 ns 21296 BM_sendVec_binderize/1024 69714 ns 32757 ns 21319 BM_sendVec_binderize/2k 75002 ns 34520 ns 20305 BM_sendVec_binderize/4k 81955 ns 39116 ns 17895 BM_sendVec_binderize/8k 95316 ns 45710 ns 15350 BM_sendVec_binderize/16k 112751 ns 54417 ns 12679 BM_sendVec_binderize/32k 146642 ns 71339 ns 9901 BM_sendVec_binderize/64k 214796 ns 104665 ns 6495
- समय से पता चलता है कि रीयल टाइम में, एक बार यात्रा करने में कितनी देरी हुई.
- सीपीयू से पता चलता है कि टेस्ट के लिए सीपीयू को शेड्यूल किए जाने पर, कुल कितना समय लगा.
- इटरेशन से पता चलता है कि टेस्ट फ़ंक्शन कितनी बार चलाया गया.
उदाहरण के लिए, आठ बाइट वाले पेलोड के लिए:
BM_sendVec_binderize/8 69974 ns 32700 ns 21296
… बाइंडर की ज़्यादा से ज़्यादा थ्रूपुट का हिसाब इस तरह लगाया जाता है:
8-बाइट पेलोड के साथ ज़्यादा से ज़्यादा थ्रूपुट = (8 * 21296)/69974 ~= 2.423 b/ns ~= 2.268 Gb/s
टेस्ट करने के विकल्प
.json फ़ॉर्मैट में नतीजे पाने के लिए, --benchmark_format=json आर्ग्युमेंट के साथ टेस्ट चलाएं:
libhwbinder_benchmark --benchmark_format=json
{
"context": {
"date": "2017-05-17 08:32:47",
"num_cpus": 4,
"mhz_per_cpu": 19,
"cpu_scaling_enabled": true,
"library_build_type": "release"
},
"benchmarks": [
{
"name": "BM_sendVec_binderize/4",
"iterations": 32342,
"real_time": 47809,
"cpu_time": 21906,
"time_unit": "ns"
},
….
}इंतज़ार का समय जांचने वाले टेस्ट चलाना
इंतज़ार का समय जांचने वाले टूल से यह पता चलता है कि क्लाइंट को लेन-देन शुरू करने, उसे मैनेज करने के लिए सर्वर प्रोसेस पर स्विच करने, और नतीजा पाने में कितना समय लगता है. इस टेस्ट में, शेड्यूलर के ऐसे गलत व्यवहारों का पता भी लगाया जाता है जिनसे लेन-देन में लगने वाले समय पर बुरा असर पड़ सकता है. जैसे, ऐसा शेड्यूलर जो प्राथमिकता के इनहेरिटेंस या सिंक फ़्लैग के साथ काम नहीं करता.
- बाइंडर के इंतज़ार का समय जांचने वाला टूल,
frameworks/native/libs/binder/tests/schd-dbg.cppमें है. - hwbinder के इंतज़ार का समय जांचने वाला टेस्ट,
system/libhwbinder/vts/performance/Latency.cppमें है.
परीक्षण के नतीजे
.json फ़ॉर्मैट में मौजूद नतीजों में, औसत/सबसे अच्छा/सबसे खराब इंतज़ार का समय और तय समय से ज़्यादा समय लगने की संख्या के आंकड़े दिखते हैं.
टेस्ट करने के विकल्प
इंतज़ार का समय जांचने के लिए, ये विकल्प इस्तेमाल किए जाते हैं:
| निर्देश | ब्यौरा |
|---|---|
-i value |
दोहराव की संख्या बताएं. |
-pair value |
प्रोसेस पेयर की संख्या बताएं. |
-deadline_us 2500 |
समयसीमा को अमेरिकन मुद्रा में बताएं. |
-v |
ज़्यादा जानकारी वाला (डीबगिंग) आउटपुट पाएं. |
-trace |
समयसीमा खत्म होने पर ट्रैकिंग रोकना. |
यहां दिए गए सेक्शन में, हर विकल्प के बारे में पूरी जानकारी दी गई है. साथ ही, इस्तेमाल के तरीके और उदाहरण के तौर पर नतीजे भी दिए गए हैं.
दोहराव की संख्या तय करना
ज़्यादा बार दोहराए जाने वाले और ज़्यादा जानकारी वाले आउटपुट को बंद करने का उदाहरण:
libhwbinder_latency -i 5000 -pair 3
{
"cfg":{"pair":3,"iterations":5000,"deadline_us":2500},
"P0":{"SYNC":"GOOD","S":9352,"I":10000,"R":0.9352,
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}
},
"P1":{"SYNC":"GOOD","S":9334,"I":10000,"R":0.9334,
"other_ms":{ "avg":0.19, "wst":2.9 , "bst":0.055, "miss":2, "meetR":0.9996},
"fifo_ms": { "avg":0.16, "wst":3.1 , "bst":0.066, "miss":1, "meetR":0.9998}
},
"P2":{"SYNC":"GOOD","S":9369,"I":10000,"R":0.9369,
"other_ms":{ "avg":0.19, "wst":4.8 , "bst":0.055, "miss":6, "meetR":0.9988},
"fifo_ms": { "avg":0.15, "wst":1.8 , "bst":0.067, "miss":0, "meetR":1}
},
"inheritance": "PASS"
}जांच के इन नतीजों में ये चीज़ें दिखती हैं:
"pair":3- एक क्लाइंट और सर्वर जोड़ा बनाता है.
"iterations": 5000- इसमें 5,000 इटरेटेशन शामिल हैं.
"deadline_us":2500- समयसीमा 2500us (2.5ms) है. ज़्यादातर लेन-देन में यह समयसीमा पूरी हो जाती है.
"I": 10000- एक बार के टेस्ट में दो (2) लेन-देन शामिल होते हैं:
- सामान्य प्राथमिकता (
CFS other) के हिसाब से एक लेन-देन - रीयल टाइम प्राथमिकता के हिसाब से एक लेन-देन (
RT-fifo)
- सामान्य प्राथमिकता (
"S": 9352- 9352 लेन-देन, एक ही सीपीयू में सिंक किए गए हैं.
"R": 0.9352- यह उस अनुपात को दिखाता है जिस पर क्लाइंट और सर्वर, एक ही सीपीयू में एक साथ सिंक होते हैं.
"other_ms":{ "avg":0.2 , "wst":2.8 , "bst":0.053, "miss":2, "meetR":0.9996}- सामान्य प्राथमिकता वाले कॉलर से किए गए सभी लेन-देन के लिए, औसत (
avg), सबसे खराब (wst), और सबसे अच्छा (bst) उदाहरण. दो लेन-देनmissसमयसीमा के बाद हुए, जिससे टारगेट पूरा करने का अनुपात (meetR) 0.9996 हो गया. "fifo_ms": { "avg":0.16, "wst":1.5 , "bst":0.067, "miss":0, "meetR":1}other_msसे मिलता-जुलता है, लेकिन क्लाइंट की ओर सेrt_fifoप्राथमिकता वाले लेन-देन के लिए. ऐसा हो सकता है (हालांकि ज़रूरी नहीं) किfifo_msका नतीजाother_msसे बेहतर हो. इसके लिए,avgऔरwstकी वैल्यू कम औरmeetRकी वैल्यू ज़्यादा होनी चाहिए. बैकग्राउंड में लोड होने पर, अंतर और भी ज़्यादा हो सकता है.
ध्यान दें: बैकग्राउंड लोड से, इंतज़ार का समय जांचने वाले टेस्ट में, थ्रुपुट के नतीजे और other_ms ट्यूपल पर असर पड़ सकता है. जब तक बैकग्राउंड लोड की प्राथमिकता, RT-fifo से कम है, तब तक सिर्फ़ fifo_ms मिलते-जुलते नतीजे दिखा सकता है.
पेयर की वैल्यू तय करना
हर क्लाइंट प्रोसेस को क्लाइंट के लिए खास तौर पर बनाई गई सर्वर प्रोसेस के साथ जोड़ा जाता है. साथ ही, हर जोड़े को किसी भी सीपीयू के लिए अलग से शेड्यूल किया जा सकता है. हालांकि, जब तक सिंक करने का फ़्लैग honor पर सेट है, तब तक लेन-देन के दौरान सीपीयू माइग्रेशन नहीं होना चाहिए.
पक्का करें कि सिस्टम पर ज़्यादा लोड न हो! ज़्यादा ट्रैफ़िक वाले सिस्टम में रीस्पॉन्स में देरी होना आम बात है. हालांकि, ज़्यादा ट्रैफ़िक वाले सिस्टम के टेस्ट के नतीजों से काम की जानकारी नहीं मिलती. ज़्यादा दबाव वाले सिस्टम की जांच करने के लिए, -pair
#cpu-1 का इस्तेमाल करें. इसके अलावा, सावधानी के साथ -pair #cpu का इस्तेमाल भी किया जा सकता है. n > #cpu के साथ -pair n का इस्तेमाल करके जांच करने से, सिस्टम पर ज़्यादा लोड पड़ता है और बेकार जानकारी जनरेट होती है.
समयसीमा की वैल्यू डालना
उपयोगकर्ताओं के हिसाब से अलग-अलग स्थितियों में टेस्ट करने (ज़रूरी शर्तें पूरी करने वाले प्रॉडक्ट पर इंतज़ार का समय जांचने) के बाद, हमने तय किया है कि 2.5 मिलीसेकंड की समयसीमा पूरी की जानी चाहिए. ज़्यादा ज़रूरी शर्तों वाले नए ऐप्लिकेशन (जैसे, 1,000 फ़ोटो/सेकंड) के लिए, समयसीमा की यह वैल्यू बदल जाएगी.
ज़्यादा जानकारी वाला आउटपुट तय करना
-v विकल्प का इस्तेमाल करने पर, ज़्यादा जानकारी वाला आउटपुट दिखता है. उदाहरण:
libhwbinder_latency -i 1 -v-------------------------------------------------- service pid: 8674 tid: 8674 cpu: 1 SCHED_OTHER 0-------------------------------------------------- main pid: 8673 tid: 8673 cpu: 1 -------------------------------------------------- client pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0-------------------------------------------------- fifo-caller pid: 8677 tid: 8678 cpu: 0 SCHED_FIFO 99 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 ??? 99-------------------------------------------------- other-caller pid: 8677 tid: 8677 cpu: 0 SCHED_OTHER 0 -------------------------------------------------- hwbinder pid: 8674 tid: 8676 cpu: 0 SCHED_OTHER 0
- सेवा थ्रेड को
SCHED_OTHERप्राथमिकता के साथ बनाया जाता है औरCPU:1मेंpid 8674के साथ चलाया जाता है. - इसके बाद, पहला लेन-देन
fifo-callerसे शुरू किया जाता है. इस लेन-देन को पूरा करने के लिए, hwbinder, सर्वर (pid: 8674 tid: 8676) की प्राथमिकता को 99 पर अपग्रेड करता है. साथ ही, इसे ट्रांज़िशन शेड्यूलिंग क्लास (???के तौर पर प्रिंट किया गया) के साथ मार्क करता है. इसके बाद, शेड्यूलर, सर्वर प्रोसेस कोCPU:0में चलाने के लिए डालता है और उसे क्लाइंट के साथ उसी सीपीयू के साथ सिंक करता है. - दूसरे लेन-देन के लिए कॉल करने वाले की प्राथमिकता
SCHED_OTHERहोती है. सर्वर अपने-आप डाउनग्रेड हो जाता है और कॉल करने वाले कोSCHED_OTHERप्राथमिकता के साथ सेवा देता है.
डीबग करने के लिए ट्रेस का इस्तेमाल करना
इंतज़ार का समय से जुड़ी समस्याओं को डीबग करने के लिए, -trace विकल्प चुना जा सकता है. इस्तेमाल किए जाने पर, इंतज़ार का समय जांचने वाला टूल, ट्रेसलॉग रिकॉर्डिंग को उसी समय रोक देता है, जब खराब इंतज़ार का समय पता चलता है. उदाहरण:
atrace --async_start -b 8000 -c sched idle workq binder_driver sync freqlibhwbinder_latency -deadline_us 50000 -trace -i 50000 -pair 3deadline triggered: halt ∓ stop trace log:/sys/kernel/debug/tracing/trace
इन कॉम्पोनेंट की वजह से, इंतज़ार का समय बढ़ सकता है:
- Android बिल्ड मोड. आम तौर पर, Eng मोड, userdebug मोड से धीमा होता है.
- फ़्रेमवर्क. फ़्रेमवर्क सेवा, बाइंडर को कॉन्फ़िगर करने के लिए
ioctlका इस्तेमाल कैसे करती है? - बाइंडर ड्राइवर. क्या ड्राइवर, ज़्यादा बारीक लेवल पर ऐक्सेस कंट्रोल करने की सुविधा देता है? क्या इसमें परफ़ॉर्मेंस को बेहतर बनाने वाले सभी पैच शामिल हैं?
- Kernel वर्शन. कर्नेल की रीयल टाइम क्षमता जितनी बेहतर होगी, नतीजे उतने ही बेहतर होंगे.
- कर्नेल कॉन्फ़िगरेशन. क्या कर्नेल कॉन्फ़िगरेशन में
DEBUG_PREEMPTऔरDEBUG_SPIN_LOCKजैसेDEBUGकॉन्फ़िगरेशन शामिल हैं? - कर्नेल शेड्यूलर. क्या कर्नेल में एनर्जी-अवेयर शेड्यूलर (ईएएस) या अलग-अलग तरह के प्रोसेसर के साथ काम करने वाला मल्टी-प्रोसेसिंग (एचएमपी) शेड्यूलर है? क्या कोई भी कर्नेल ड्राइवर (
cpu-freqड्राइवर,cpu-idleड्राइवर,cpu-hotplugवगैरह) शेड्यूलर पर असर डालता है?