
लगातार इंटिग्रेशन वाले डैशबोर्ड को स्केलेबल, बेहतर परफ़ॉर्म करने वाला, और ज़रूरत के मुताबिक बनाने के लिए, VTS डैशबोर्ड के बैकएंड को ध्यान से डिज़ाइन करना होगा. इसके लिए, डेटाबेस की सुविधाओं को अच्छी तरह समझना ज़रूरी है. Google Cloud Datastore एक NoSQL डेटाबेस है. यह लेन-देन के लिए ACID (ऐसिड) गारंटी और आखिर में डेटा के एक जैसा होने की सुविधा देता है. साथ ही, इकाई के ग्रुप में डेटा के एक जैसा होने की सुविधा भी देता है. हालांकि, इसका स्ट्रक्चर एसक्यूएल डेटाबेस (और Cloud Bigtable) से काफ़ी अलग है. टेबल, पंक्तियों, और सेल के बजाय, इसमें तरह, इकाइयां, और प्रॉपर्टी होती हैं.
नीचे दिए गए सेक्शन में, VTS डैशबोर्ड वेब सेवा के लिए असरदार बैकएंड बनाने के लिए, डेटा स्ट्रक्चर और क्वेरी पैटर्न के बारे में बताया गया है.
इकाइयां
नीचे दी गई इकाइयां, वीटीएस टेस्ट रन से मिली खास जानकारी और संसाधनों को सेव करती हैं:
- इकाई की जांच करें. किसी खास टेस्ट के टेस्ट रन के बारे में मेटाडेटा सेव करता है. इसकी कुंजी, टेस्ट का नाम है. इसकी प्रॉपर्टी में, टेस्ट के पास होने की संख्या, टेस्ट के पास न होने की संख्या, और टेस्ट केस के ब्रेक होने की सूची शामिल होती है. यह सूची, सूचना देने वाली जॉब के अपडेट होने के बाद से बनती है.
- टेस्ट रन इकाई. इसमें किसी खास टेस्ट के रन का मेटाडेटा शामिल होता है. इसमें टेस्ट शुरू और खत्म होने के टाइमस्टैंप, टेस्ट के बिल्ड आईडी, पास और फ़ेल हुए टेस्ट केस की संख्या, रन का टाइप (उदाहरण के लिए, सबमिट करने से पहले, सबमिट करने के बाद या लोकल), लॉग लिंक की सूची, होस्ट मशीन का नाम, और कवरेज की खास जानकारी की संख्या सेव होनी चाहिए.
- डिवाइस की जानकारी देने वाली इकाई. इसमें टेस्ट के दौरान इस्तेमाल किए गए डिवाइसों की जानकारी होती है. इसमें डिवाइस का बिल्ड आईडी, प्रॉडक्ट का नाम, बिल्ड टारगेट, शाखा, और एबीआई की जानकारी शामिल होती है. इसे टेस्ट रन इकाई से अलग से सेव किया जाता है, ताकि एक से ज़्यादा डिवाइसों पर टेस्ट रन एक साथ चलाए जा सकें.
- प्रोफ़ाइलिंग पॉइंट रन इकाई. टेस्ट रन के दौरान, प्रोफ़ाइलिंग के किसी खास पॉइंट के लिए इकट्ठा किए गए डेटा की खास जानकारी देता है. इसमें प्रोफ़ाइलिंग डेटा के ऐक्सिस लेबल, प्रोफ़ाइलिंग पॉइंट का नाम, वैल्यू, टाइप, और रिग्रेशन मोड के बारे में बताया गया है.
- कवरेज इकाई. इसमें किसी एक फ़ाइल के लिए इकट्ठा किए गए कवरेज डेटा की जानकारी दी जाती है. इसमें Git प्रोजेक्ट की जानकारी, फ़ाइल पाथ, और सोर्स फ़ाइल में हर लाइन के लिए कवरेज की संख्या की सूची होती है.
- टेस्ट केस रन इकाई. इससे किसी टेस्ट केस के नतीजे के बारे में पता चलता है. इसमें टेस्ट केस का नाम और उसका नतीजा शामिल होता है.
- उपयोगकर्ता की पसंदीदा इकाई. हर उपयोगकर्ता की सदस्यता को किसी इकाई में दिखाया जा सकता है. इसमें, टेस्ट का रेफ़रंस और App Engine उपयोगकर्ता सेवा से जनरेट किया गया उपयोगकर्ता आईडी शामिल होता है. इससे, दोनों तरफ़ से क्वेरी करने की सुविधा मिलती है. जैसे, किसी टेस्ट की सदस्यता लेने वाले सभी उपयोगकर्ताओं के लिए और किसी उपयोगकर्ता के पसंदीदा सभी टेस्ट के लिए.
इकाई का ग्रुप बनाना
हर टेस्ट मॉड्यूल, इकाई ग्रुप के रूट को दिखाता है. टेस्ट रन इकाइयां, इस ग्रुप की चाइल्ड और डिवाइस इकाइयों, प्रोफ़ाइलिंग पॉइंट इकाइयों, और कवरेज इकाइयों के लिए पैरंट, दोनों होती हैं. ये इकाइयां, टेस्ट और टेस्ट रन के पैरंट के हिसाब से काम करती हैं.
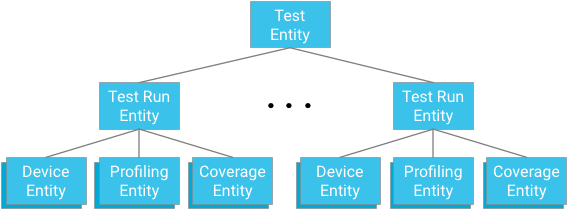
अहम जानकारी: पैतृक संबंधों को डिज़ाइन करते समय, आपको डेटाबेस की सीमाओं के हिसाब से, असरदार और लगातार क्वेरी करने के तरीके उपलब्ध कराने होंगे.
फ़ायदे
एक जैसी शर्तें लागू करने की ज़रूरी शर्त से यह पक्का होता है कि जब तक किसी लेन-देन को स्वीकार नहीं किया जाता, तब तक आने वाले समय में होने वाले लेन-देन पर उसका असर नहीं पड़ेगा. साथ ही, यह भी पक्का होता है कि पिछले लेन-देन, मौजूदा लेन-देन के लिए दिखें. Cloud Datastore में, इकाई को ग्रुप करने से ग्रुप में डेटा को पढ़ने और उसमें बदलाव करने की सुविधा बेहतर हो जाती है. इस मामले में, टेस्ट मॉड्यूल से जुड़े सभी टेस्ट रन और डेटा शामिल है. इससे ये फ़ायदे मिलते हैं:
- सूचना वाली जॉब की मदद से, टेस्ट मॉड्यूल की स्थिति को पढ़ने और अपडेट करने की प्रोसेस को एटॉमिक माना जा सकता है
- टेस्ट मॉड्यूल में, टेस्ट केस के नतीजों को एक जैसा देखने की गारंटी
- वंशानुगत पेड़ों में तेज़ी से क्वेरी करना
सीमाएं
किसी एंटिटी ग्रुप में, एक सेकंड में एक एंटिटी से ज़्यादा एंटिटी को लिखने का सुझाव नहीं दिया जाता, क्योंकि कुछ एंटिटी को अस्वीकार किया जा सकता है. जब तक सूचना वाली जॉब और अपलोड करने की प्रोसेस, एक सेकंड में एक बार लिखने की दर से तेज़ी से नहीं होती, तब तक स्ट्रक्चर मज़बूत होता है और डेटा लगातार एक जैसा रहता है.
आखिरकार, हर सेकंड में हर टेस्ट मॉड्यूल के लिए एक बार लिखने की सीमा सही है, क्योंकि आम तौर पर, टेस्ट को चलाने में कम से कम एक मिनट लगता है. इसमें, VTS फ़्रेमवर्क का ओवरहेड भी शामिल है. जब तक किसी टेस्ट को लगातार 60 से ज़्यादा अलग-अलग होस्ट पर एक साथ नहीं चलाया जा रहा है, तब तक डेटा लिखने में कोई समस्या नहीं आ सकती. यह और भी मुश्किल हो जाता है, क्योंकि हर मॉड्यूल एक टेस्ट प्लान का हिस्सा होता है. आम तौर पर, इस टेस्ट प्लान को पूरा करने में एक घंटे से ज़्यादा समय लगता है. अगर होस्ट एक ही समय पर टेस्ट चलाते हैं, तो गड़बड़ियों को आसानी से मैनेज किया जा सकता है.इससे, एक ही होस्ट पर लिखने की प्रोसेस में कुछ समय के लिए रुकावट आती है. उदाहरण के लिए, लिखने से जुड़ी गड़बड़ियों को ठीक करके फिर से कोशिश करना.
स्केलिंग से जुड़ी बातें
टेस्ट रन के लिए ज़रूरी नहीं है कि टेस्ट को पैरंट के तौर पर शामिल किया जाए.उदाहरण के लिए, इसमें कोई दूसरी कुंजी शामिल की जा सकती है और टेस्ट का नाम, टेस्ट शुरू होने का समय प्रॉपर्टी के तौर पर शामिल किया जा सकता है. हालांकि, इससे एक जैसी क्वालिटी के बजाय, अलग-अलग क्वालिटी वाली क्वेरी मिल सकती हैं. उदाहरण के लिए, हो सकता है कि सूचना जॉब को किसी टेस्ट मॉड्यूल में, हाल ही में चलाए गए टेस्ट के एक-दूसरे से मेल खाने वाले स्नैपशॉट न दिखें. इसका मतलब है कि हो सकता है कि ग्लोबल स्टेटस में, टेस्ट के क्रम की पूरी तरह से सटीक जानकारी न दिखे. इससे, एक ही टेस्ट मॉड्यूल में टेस्ट रन के डिसप्ले पर भी असर पड़ सकता है. ऐसा ज़रूरी नहीं है कि यह रन क्रम का एक जैसा स्नैपशॉट हो. आखिर में, स्नैपशॉट एक जैसा रहेगा. हालांकि, इस बात की कोई गारंटी नहीं है कि इसमें सबसे नया डेटा होगा.
टेस्ट केस
कई टेस्ट केस वाले बड़े टेस्ट भी समस्या पैदा कर सकते हैं. काम करने से जुड़ी दो सीमाएं हैं. पहला, इकाई के ग्रुप में एक सेकंड में ज़्यादा से ज़्यादा एक इकाई लिखी जा सकती है. दूसरा, लेन-देन का साइज़ 500 इकाइयों से ज़्यादा नहीं होना चाहिए.
एक तरीका यह है कि आप ऐसे टेस्ट केस की जानकारी दें जिसमें टेस्ट को किसी पैरंट के तौर पर चलाया गया हो. यह उसी तरह है जिस तरह कवरेज डेटा, प्रोफ़ाइलिंग डेटा, और डिवाइस की जानकारी को सेव किया जाता है:
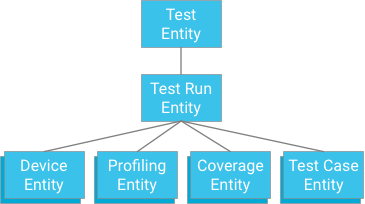
इस तरीके से, एक ही बार में एक ही काम पूरा किया जा सकता है और डेटा में एक जैसी जानकारी मिलती है. हालांकि, इससे टेस्ट पर कई पाबंदियां भी लगती हैं: अगर कोई लेन-देन 500 इकाइयों तक सीमित है, तो किसी टेस्ट में 498 से ज़्यादा टेस्ट केस नहीं हो सकते. ऐसा तब माना जाता है, जब कवरेज या प्रोफ़ाइलिंग डेटा न हो. अगर किसी टेस्ट में ज़्यादा ट्रांज़ैक्शन होते हैं, तो एक ट्रांज़ैक्शन में एक साथ सभी टेस्ट केस के नतीजे नहीं लिखे जा सकते. साथ ही, टेस्ट केस को अलग-अलग ट्रांज़ैक्शन में बांटने पर, इकाई ग्रुप के लिखने की ज़्यादा से ज़्यादा दर, हर सेकंड एक बार के बजाय ज़्यादा हो सकती है. इस समाधान से परफ़ॉर्मेंस पर असर पड़ेगा. इसलिए, इसका सुझाव नहीं दिया जाता.
हालांकि, टेस्ट केस के नतीजों को टेस्ट रन के चाइल्ड के तौर पर सेव करने के बजाय, टेस्ट केस को अलग से सेव किया जा सकता है. साथ ही, उनकी कुंजियों को टेस्ट रन में दिया जा सकता है. टेस्ट रन में, टेस्ट केस की इकाइयों के आइडेंटिफ़ायर की सूची होती है:
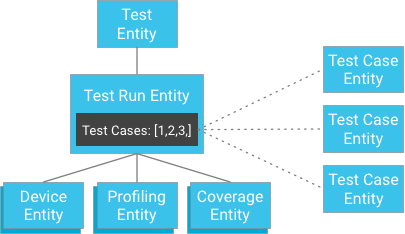
पहली नज़र में, ऐसा लग सकता है कि यह 'एक जैसी जानकारी' की गारंटी को तोड़ता है. हालांकि, अगर क्लाइंट के पास टेस्ट रन इकाई और टेस्ट केस आइडेंटिफ़ायर की सूची है, तो उसे क्वेरी बनाने की ज़रूरत नहीं है. इसके बजाय, वह सीधे अपने आइडेंटिफ़ायर से टेस्ट केस पा सकता है. यह हमेशा एक जैसा होता है. इस तरीके से, टेस्ट रन में टेस्ट केस की संख्या से जुड़ी पाबंदी को कम किया जा सकता है. साथ ही, इकाई ग्रुप में ज़्यादा लिखने की ज़रूरत के बिना, बेहतर तरीके से काम किया जा सकता है.
डेटा ऐक्सेस करने के पैटर्न
VTS डैशबोर्ड, डेटा ऐक्सेस करने के इन पैटर्न का इस्तेमाल करता है:
- उपयोगकर्ता के पसंदीदा आइटम. उपयोगकर्ता की पसंदीदा इकाइयों पर, बराबरी वाले फ़िल्टर का इस्तेमाल करके क्वेरी की जा सकती है. इन इकाइयों में, प्रॉपर्टी के तौर पर कोई खास App Engine उपयोगकर्ता ऑब्जेक्ट होना चाहिए.
- लिस्टिंग की जांच करना. टेस्ट की इकाइयों की आसान क्वेरी. होम पेज को रेंडर करने के लिए बैंडविड्थ कम करने के लिए, पास और फ़ेल होने की संख्या पर प्रॉजेक्शन का इस्तेमाल किया जा सकता है. इससे, सूचना देने वाली जॉब के लिए इस्तेमाल किए गए, फ़ेल हुए टेस्ट केस आईडी और अन्य मेटाडेटा की संभावित रूप से लंबी सूची को हटाया जा सकता है.
- टेस्ट रन. टेस्ट रन इकाइयों के लिए क्वेरी करने के लिए, की (टाइमस्टैंप) के हिसाब से क्रम से लगाने और टेस्ट रन प्रॉपर्टी, जैसे कि बिल्ड आईडी, पास होने की संख्या वगैरह के हिसाब से फ़िल्टर करने की ज़रूरत होती है. टेस्ट इकाई की सेल के साथ एक पैरंट क्वेरी करने पर, डेटा को लगातार पढ़ा जा सकता है. इस समय, टेस्ट केस के सभी नतीजों को, टेस्ट रन प्रॉपर्टी में सेव किए गए आईडी की सूची का इस्तेमाल करके वापस पाया जा सकता है. साथ ही, डेटास्टोर के 'प्रॉपर्टी पाने' ऑपरेशन की वजह से, यह भी पक्का किया जा सकता है कि नतीजे एक जैसे हों.
- प्रोफ़ाइल और कवरेज डेटा. किसी टेस्ट से जुड़ी प्रोफ़ाइलिंग या कवरेज डेटा के लिए क्वेरी करने पर, टेस्ट के किसी भी अन्य डेटा को भी वापस नहीं पाया जा सकता. जैसे, अन्य प्रोफ़ाइलिंग/कवरेज डेटा, टेस्ट केस डेटा वगैरह. टेस्ट और टेस्ट रन इकाई की कुंजियों का इस्तेमाल करने वाली अंसियर क्वेरी, टेस्ट रन के दौरान रिकॉर्ड किए गए सभी प्रोफ़ाइलिंग पॉइंट को वापस लाएगी. साथ ही, प्रोफ़ाइलिंग पॉइंट के नाम या फ़ाइल नाम के हिसाब से फ़िल्टर करके, एक प्रोफ़ाइलिंग या कवरेज इकाई को वापस लाया जा सकता है. अंसियर क्वेरी की प्रकृति के हिसाब से, यह कार्रवाई पूरी तरह से एक जैसी होती है.
यूज़र इंटरफ़ेस (यूआई) और इन डेटा पैटर्न के स्क्रीनशॉट के बारे में ज़्यादा जानने के लिए, वीटीएस डैशबोर्ड यूआई देखें.