
Um ein skalierbares, leistungsstarkes und flexibles Dashboard für die kontinuierliche Integration zu unterstützen, muss das VTS-Dashboard-Backend sorgfältig mit einem guten Verständnis der Datenbankfunktionen entworfen werden. Google Cloud Datastore ist eine NoSQL-Datenbank, die ACID-Transaktionen und die eventuale Konsistenz sowie eine strikte Konsistenz innerhalb von Entitätengruppen bietet. Die Struktur unterscheidet sich jedoch stark von SQL-Datenbanken (und sogar von Cloud Bigtable): Anstelle von Tabellen, Zeilen und Zellen gibt es Arten, Entitäten und Eigenschaften.
In den folgenden Abschnitten werden die Datenstruktur und Abfragemuster beschrieben, die für die Erstellung eines effektiven Backends für den VTS Dashboard-Webdienst erforderlich sind.
Entitäten
In den folgenden Entitäten werden Zusammenfassungen und Ressourcen aus VTS-Tests gespeichert:
- Testentität Hier werden Metadaten zu Testläufen eines bestimmten Tests gespeichert. Der Schlüssel ist der Testname und die Eigenschaften umfassen die Anzahl der Fehler, die Anzahl der bestandenen Tests und die Liste der Testfallausfälle, die seit der Aktualisierung durch die Benachrichtigungsjobs aufgetreten sind.
- Testlauf-Entität Enthält Metadaten aus Ausführungen eines bestimmten Tests. Sie muss die Zeitstempel für den Testbeginn und das Testende, die ID des Test-Builds, die Anzahl der bestandenen und fehlgeschlagenen Testfälle, die Art der Ausführung (z.B. vor dem Einreichen, nach dem Einreichen oder lokal), eine Liste der Protokolllinks, den Namen des Hostcomputers und die Zusammenfassung der Abdeckung enthalten.
- Device Information Entity Enthält Details zu den während des Tests verwendeten Geräten. Sie enthält die Build-ID des Geräts, den Produktnamen, das Build-Ziel, den Branch und ABI-Informationen. Dieser wird getrennt von der Testlauf-Entität gespeichert, um Mehrgeräte-Testläufe auf „Eins-zu-viele“-Weise zu unterstützen.
- Profilierungspunkt – Ausführungseinheit Hier werden die Daten zusammengefasst, die für einen bestimmten Profilierungspunkt innerhalb eines Testlaufs erfasst wurden. Hier werden die Achsenlabels, der Name des Profilierungspunkts, die Werte, der Typ und der Regressionsmodus der Profilierungsdaten beschrieben.
- Abdeckungsentität Beschreibt die Abdeckungsdaten, die für eine Datei erfasst wurden. Sie enthält die Informationen zum Git-Projekt, den Dateipfad und die Liste der Abdeckungszahlen pro Zeile in der Quelldatei.
- Testlauf-Entität Beschreibt das Ergebnis eines bestimmten Testfalls aus einem Testlauf, einschließlich des Namens des Testfalls und des Ergebnisses.
- Nutzerfavoriten-Entität Jedes Nutzerabo kann in einem Objekt dargestellt werden, das einen Verweis auf den Test und die Nutzer-ID enthält, die vom App Engine-Nutzerdienst generiert wurde. So können effiziente bidirektionale Abfragen durchgeführt werden, d.h. für alle Nutzer, die einen Test abonniert haben, und für alle Tests, die von einem Nutzer zu Favoriten hinzugefügt wurden.
Entitätengruppierung
Jedes Testmodul stellt die Wurzel einer Entitätengruppe dar. Testlauf-Entitäten sind sowohl untergeordnet als auch übergeordnet zu Geräte-, Profiling-Punkt- und Abdeckungs-Entitäten, die für den jeweiligen Test und Testlauf relevant sind.
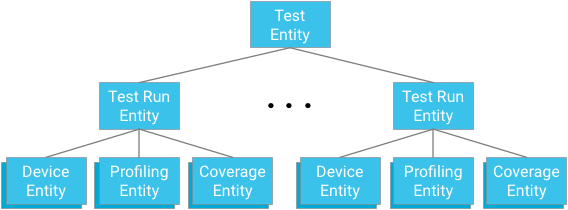
Wichtig:Beim Entwerfen von Verwandtschaftsbeziehungen müssen Sie die Notwendigkeit, effektive und konsistente Abfragemechanismen bereitzustellen, mit den Einschränkungen der Datenbank in Einklang bringen.
Vorteile
Die Konsistenzvoraussetzung sorgt dafür, dass zukünftige Vorgänge die Auswirkungen einer Transaktion erst sehen, wenn sie committet wurde, und dass Transaktionen in der Vergangenheit für aktuelle Vorgänge sichtbar sind. In Cloud Datastore werden durch die Entitätengruppierung Inseln mit starker Lese- und Schreibkonsistenz innerhalb der Gruppe erstellt. In diesem Fall sind das alle Testläufe und Daten, die sich auf ein Testmodul beziehen. Das bietet folgende Vorteile:
- Lese- und Aktualisierungsvorgänge am Testmodulstatus durch Benachrichtigungsjobs können als atomar behandelt werden.
- Einheitliche Ansicht der Testfallergebnisse innerhalb von Testmodulen
- Schnellere Abfragen in Stammbäumen
Beschränkungen
Es wird nicht empfohlen, mit einer Geschwindigkeit von mehr als einer Entität pro Sekunde in eine Entitätengruppe zu schreiben, da einige Schreibvorgänge möglicherweise abgelehnt werden. Solange die Benachrichtigungsjobs und der Upload nicht schneller als ein Schreibvorgang pro Sekunde erfolgen, ist die Struktur solide und garantiert Strong Consistency.
Die Beschränkung auf einen Schreibvorgang pro Testmodul pro Sekunde ist letztendlich sinnvoll, da Testläufe in der Regel mindestens eine Minute dauern, einschließlich des Overheads des VTS-Frameworks. Sofern ein Test nicht kontinuierlich auf mehr als 60 verschiedenen Hosts ausgeführt wird, kann es zu keinem Schreibengpass kommen. Das ist umso unwahrscheinlicher, da jedes Modul Teil eines Testplans ist, der oft länger als eine Stunde dauert. Anomalien können leicht behandelt werden, wenn die Hosts die Tests gleichzeitig ausführen und es zu kurzen Schreibspitzen auf denselben Hosts kommt (z.B. durch Auffangen von Schreibfehlern und erneuten Versuch).
Aspekte bei der Skalierung
Ein Testlauf muss nicht unbedingt den Test als übergeordnetes Element haben (z. B. könnte er einen anderen Schlüssel und den Testnamen sowie den Teststartzeitpunkt als Eigenschaften haben). Dadurch wird jedoch die starke Konsistenz durch die eventuale Konsistenz ersetzt. Beispielsweise wird dem Benachrichtigungsjob möglicherweise kein gegenseitig konsistenter Snapshot der letzten Tests innerhalb eines Testmoduls angezeigt. Das bedeutet, dass der globale Status möglicherweise nicht genau die Abfolge der Tests widerspiegelt. Dies kann sich auch auf die Darstellung von Testläufen innerhalb eines einzelnen Testmoduls auswirken, das nicht unbedingt einen konsistenten Snapshot der Ablaufsequenz darstellt. Irgendwann ist der Snapshot konsistent, aber es gibt keine Garantie dafür, dass die neuesten Daten auch konsistent sind.
Testläufe
Ein weiteres potenzielles Nadelöhr sind große Tests mit vielen Testfällen. Die beiden operativen Einschränkungen sind der maximale Schreibdurchsatz innerhalb einer Entitätengruppe von einer Transaktion pro Sekunde sowie eine maximale Transaktionsgröße von 500 Entitäten.
Eine Möglichkeit wäre, einen Testfall anzugeben, der einen Testlauf als übergeordneten Element hat (ähnlich wie Abdeckungsdaten, Profilierungsdaten und Geräteinformationen gespeichert werden):
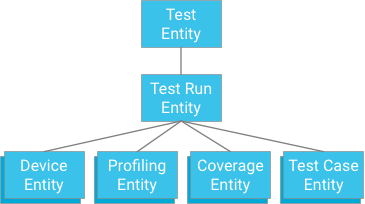
Dieser Ansatz bietet zwar Atomarität und Konsistenz, schränkt aber die Tests stark ein: Wenn eine Transaktion auf 500 Entitäten beschränkt ist, kann ein Test maximal 498 Testfälle haben (vorausgesetzt, es gibt keine Abdeckungs- oder Profilierungsdaten). Wenn ein Test diesen Wert überschreitet, können nicht alle Testfallergebnisse mit einer einzigen Transaktion auf einmal geschrieben werden. Wenn die Testfälle in separate Transaktionen unterteilt werden, kann der maximale Schreibdurchsatz der Entitätengruppe von einer Iteration pro Sekunde überschritten werden. Da diese Lösung nicht gut skaliert, ohne die Leistung zu beeinträchtigen, wird sie nicht empfohlen.
Anstatt die Testfallergebnisse als untergeordnete Elemente des Testlaufs zu speichern, können die Testfälle unabhängig gespeichert und ihre Schlüssel für den Testlauf bereitgestellt werden. Ein Testlauf enthält eine Liste der IDs der Testfall-Entitäten:
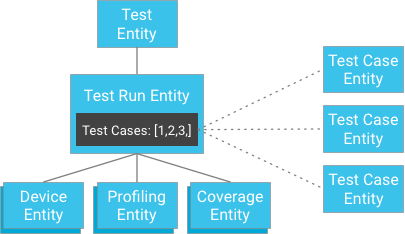
Auf den ersten Blick scheint dies die Garantie für die strikte Konsistenz zu verletzen. Wenn der Kunde jedoch eine Testlauf-Entität und eine Liste mit Testfall-IDs hat, muss er keine Abfrage erstellen. Er kann die Testfälle stattdessen direkt anhand ihrer IDs abrufen, die immer konsistent sind. Mit diesem Ansatz wird die Einschränkung der Anzahl der Testfälle, die ein Testlauf haben kann, erheblich verringert. Gleichzeitig wird eine starke Konsistenz erreicht, ohne dass zu viele Schreibvorgänge innerhalb einer Entitätsgruppe drohen.
Datenzugriffsmuster
Im VTS-Dashboard werden die folgenden Datenzugriffsmuster verwendet:
- Nutzerfavoriten Sie können mit einem Gleichheitsfilter auf Nutzerfavoriten-Entitäten abgefragt werden, die das betreffende App Engine-Nutzerobjekt als Property haben.
- Testeintrag Einfache Abfrage von Testentitäten. Um die Bandbreite für das Rendern der Startseite zu reduzieren, kann eine Projektion für die Anzahl der bestandenen und fehlgeschlagenen Tests verwendet werden, um die potenziell lange Liste der IDs der fehlgeschlagenen Testfälle und andere Metadaten zu entfernen, die von den Benachrichtigungsjobs verwendet werden.
- Testläufe Für Abfragen nach Testlaufentitäten ist eine Sortierung nach dem Schlüssel (Zeitstempel) und eine mögliche Filterung nach den Testlaufeigenschaften wie Build-ID, Anzahl der bestandenen Tests usw. erforderlich. Durch Ausführen einer übergeordneten Abfrage mit einem Testentitätsschlüssel ist die Lesevorgänge sehr konsistent. An diesem Punkt können alle Testfallergebnisse mithilfe der Liste der IDs abgerufen werden, die in einer Eigenschaft für den Testlauf gespeichert sind. Aufgrund der Art der Get-Vorgänge in der Datenbank ist außerdem garantiert, dass die Ergebnisse einheitlich sind.
- Profilierungs- und Abdeckungsdaten Sie können eine Abfrage für Profiling- oder Abdeckungsdaten ausführen, die mit einem Test verknüpft sind, ohne dass andere Testlaufdaten (z. B. andere Profiling-/Abdeckungsdaten oder Testfalldaten) abgerufen werden. Mit einer übergeordneten Abfrage, die die Entitätsschlüssel für den Test und den Testlauf verwendet, werden alle während des Testlaufs erfassten Profiling-Punkte abgerufen. Wenn Sie außerdem nach dem Namen oder Dateinamen des Profiling-Punkts filtern, kann eine einzelne Profiling- oder Abdeckungsentität abgerufen werden. Aufgrund der Natur von Ancestor-Abfragen ist dieser Vorgang strikt konsistent.
Details zur Benutzeroberfläche und Screenshots dieser Datenmuster in Aktion finden Sie unter VTS-Dashboard-Benutzeroberfläche.