
برای پشتیبانی از داشبورد یکپارچهسازی پیوسته که مقیاسپذیر، کارآمد و انعطافپذیر است، باطن داشبورد VTS باید با دقت و با درک قوی از عملکرد پایگاه داده طراحی شود. Google Cloud Datastore یک پایگاه داده NoSQL است که ضمانتهای ACID تراکنشی و ثبات نهایی و همچنین ثبات قوی در گروههای موجود را ارائه میدهد. با این حال، ساختار بسیار متفاوت از SQLdatabases (و حتی Cloud Bigtable) است. به جای جداول، ردیف ها و سلول ها انواع، موجودیت ها و ویژگی ها وجود دارد.
بخش های زیر ساختار داده و الگوهای پرس و جو را برای ایجاد یک Backend موثر برای وب سرویس VTS Dashboard تشریح می کند.
نهادها
موجودیتهای زیر خلاصهها و منابع را از اجرای آزمایشی VTS ذخیره میکنند:
- موجودیت آزمایشی ابردادههای مربوط به آزمایشهای آزمایشی خاص را ذخیره میکند. کلید آن نام تست است و ویژگیهای آن شامل تعداد شکست، تعداد قبولی، و لیست شکستگیهای مورد آزمایش از زمانی که مشاغل هشدار آن را بهروزرسانی میکنند، میشود.
- Test Run Entity حاوی متادیتا از اجرای یک آزمایش خاص است. باید مُهرهای زمان شروع و پایان آزمایش، شناسه ساخت آزمایشی، تعداد موارد تست موفق و ناموفق، نوع اجرا (مثلاً پیش ارسال، پس از ارسال، یا محلی)، فهرستی از پیوندهای گزارش، نام دستگاه میزبان، و تعداد خلاصه پوشش را ذخیره کند.
- موجودیت اطلاعات دستگاه حاوی جزئیات مربوط به دستگاه های مورد استفاده در طول اجرای آزمایشی است. این شامل شناسه ساخت دستگاه، نام محصول، هدف ساخت، شاخه و اطلاعات ABI است. این به طور جداگانه از موجودیت اجرای آزمایشی ذخیره می شود تا از اجرای آزمایشی چند دستگاهی به صورت یک به چند پشتیبانی کند.
- نمایه سازی نقطه اجرا موجودیت . دادههای جمعآوریشده برای یک نقطه پروفایل خاص را در یک اجرای آزمایشی خلاصه میکند. برچسبهای محور، نام نقطه پروفایل، مقادیر، نوع و حالت رگرسیون دادههای پروفایل را توصیف میکند.
- نهاد پوشش . داده های پوشش جمع آوری شده برای یک فایل را شرح می دهد. این شامل اطلاعات پروژه Git، مسیر فایل، و فهرست تعداد پوشش در هر خط در فایل منبع است.
- Test Case Run Entity . نتیجه یک مورد آزمایشی خاص را از یک آزمایش آزمایشی، از جمله نام مورد آزمایشی و نتیجه آن، توصیف میکند.
- موجودیت مورد علاقه کاربر هر اشتراک کاربر را می توان در یک موجودیت حاوی ارجاع به آزمایش و شناسه کاربری ایجاد شده از سرویس کاربر App Engine نشان داد. این امکان پرس و جوی دو جهته کارآمد را فراهم می کند (یعنی برای همه کاربرانی که در یک آزمایش مشترک هستند و برای همه آزمایش های مورد علاقه کاربر).
گروه بندی موجودیت
هر ماژول تست ریشه یک گروه موجودیت را نشان می دهد. نهادهای اجرای آزمایشی هم فرزندان این گروه و هم والدین برای نهادهای دستگاه، نهادهای نقطه نمایه، و نهادهای پوشش مربوط به اجداد آزمایشی و آزمایشی مربوطه هستند.
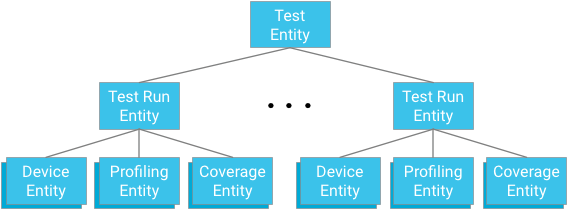
نکته کلیدی: هنگام طراحی روابط اجدادی، باید بین نیاز به ارائه مکانیسمهای پرسوجو مؤثر و سازگار در برابر محدودیتهای اعمالشده توسط پایگاه داده تعادل برقرار کنید.
مزایا
الزام سازگاری تضمین میکند که عملیاتهای آتی اثرات یک تراکنش را تا زمانی که انجام نشود، نخواهند دید و تراکنشهای گذشته برای عملیات فعلی قابل مشاهده است. در Cloud Datastore، گروهبندی موجودیت، جزیرههایی از سازگاری خواندن و نوشتن قوی در گروه ایجاد میکند، که در این مورد، همه آزمایشها و دادههای مربوط به یک ماژول آزمایشی است. این مزایای زیر را ارائه می دهد:
- خواندن و به روز رسانی برای آزمایش وضعیت ماژول توسط مشاغل هشدار را می توان به عنوان اتمی در نظر گرفت
- مشاهده منسجم تضمین شده از نتایج مورد آزمایش در ماژول های آزمون
- پرس و جو سریعتر در درختان اجدادی
محدودیت ها
نوشتن برای یک گروه موجودیت با نرخی سریعتر از یک موجودیت در ثانیه توصیه نمی شود زیرا ممکن است برخی از نوشته ها رد شوند. تا زمانی که کارهای هشدار و آپلود با سرعتی بیشتر از یک نوشتن در ثانیه اتفاق نیفتد، ساختار محکم است و ثبات قوی را تضمین می کند.
در نهایت، سقف یک نوشتن در هر ماژول تست در ثانیه معقول است زیرا اجرای آزمایشی معمولا حداقل یک دقیقه از جمله سربار چارچوب VTS طول می کشد. مگر اینکه یک آزمایش به طور همزمان روی بیش از 60 میزبان مختلف اجرا شود، نمی توان گلوگاه نوشتن وجود داشت. این امر با توجه به اینکه هر ماژول بخشی از یک برنامه آزمایشی است که اغلب بیش از یک ساعت طول می کشد، بعید تر می شود. اگر میزبانها آزمایشها را همزمان اجرا کنند، ناهنجاریها را میتوان به راحتی کنترل کرد، که باعث میشود دورههای کوتاهی از نوشتن برای همان میزبانها ایجاد شود (مثلاً با گرفتن خطاهای نوشتن و تلاش مجدد).
ملاحظات مقیاس بندی
یک اجرای آزمایشی لزوماً نیازی به داشتن آزمایش به عنوان والد ندارد (مثلاً می تواند کلید دیگری داشته باشد و نام آزمایش، زمان شروع آزمایش را به عنوان ویژگی داشته باشد). با این حال، این یک ثبات قوی را با ثبات نهایی مبادله خواهد کرد. به عنوان مثال، کار هشدار ممکن است یک عکس فوری متقابل از آخرین آزمایشهای آزمایشی در یک ماژول آزمایشی مشاهده نکند، به این معنی که وضعیت جهانی ممکن است نمایشی کاملاً دقیق از دنباله اجرای آزمایشی را نشان ندهد. این همچنین ممکن است بر نمایش اجراهای آزمایشی در یک ماژول آزمایشی تأثیر بگذارد، که ممکن است لزوماً یک عکس فوری ثابت از دنباله اجرا نباشد. در نهایت عکس فوری ثابت خواهد بود، اما هیچ تضمینی وجود ندارد که جدیدترین داده ها باشد.
موارد تست
یکی دیگر از گلوگاه های بالقوه آزمایش های بزرگ با موارد آزمایشی زیاد است. دو محدودیت عملیاتی عبارتند از حداکثر توان نوشتن در یک گروه موجودیت یک در ثانیه، همراه با حداکثر اندازه تراکنش 500 موجودیت.
یک رویکرد می تواند مشخص کردن یک مورد آزمایشی باشد که دارای یک آزمایش آزمایشی به عنوان یک اجداد باشد (مشابه نحوه ذخیره داده های پوشش، داده های پروفایل و اطلاعات دستگاه):
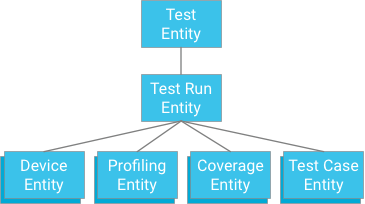
در حالی که این رویکرد اتمی و سازگاری را ارائه میکند، محدودیتهای شدیدی را بر آزمایشها تحمیل میکند: اگر یک تراکنش به 500 موجودیت محدود شود، آنوقت یک آزمایش نمیتواند بیش از 498 مورد آزمایشی داشته باشد (با فرض اینکه دادههای پوشش یا پروفایل وجود نداشته باشد). اگر آزمایشی بیش از این باشد، آنگاه یک تراکنش نمیتواند همه نتایج آزمایشی را بهطور همزمان بنویسد، و تقسیم موارد آزمایشی به تراکنشهای جداگانه میتواند از حداکثر توان نوشتن گروه موجودیت یک تکرار در ثانیه بیشتر شود. از آنجایی که این راه حل بدون کاهش عملکرد به خوبی مقیاس نخواهد شد، توصیه نمی شود.
با این حال، بهجای ذخیرهسازی نتایج مورد آزمایشی بهعنوان فرزندان آزمایش، موارد آزمایشی را میتوان بهطور مستقل ذخیره کرد و کلیدهای آنها را در اجرای آزمایشی ارائه کرد (یک اجرای آزمایشی حاوی فهرستی از شناسههای موجودیتهای مورد آزمایشی است):
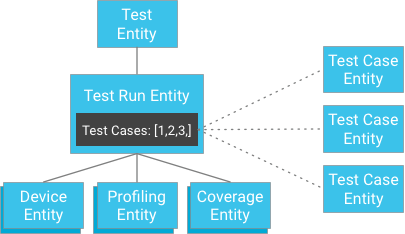
در نگاه اول، ممکن است به نظر برسد که این تضمین قوام قوی را زیر پا می گذارد. با این حال، اگر مشتری یک موجودیت اجرای آزمایشی و لیستی از شناسههای مورد آزمایشی داشته باشد، نیازی به ساخت پرس و جو ندارد. در عوض میتواند مستقیماً موارد آزمایشی را با شناسههای آنها دریافت کند، که همیشه ثابت است. این رویکرد محدودیت تعداد موارد آزمایشی را که ممکن است یک اجرای آزمایشی ممکن است داشته باشد، کاهش می دهد، در حالی که ثبات قوی را بدون تهدید نوشتن بیش از حد در یک گروه موجودیت به دست می آورد.
الگوهای دسترسی به داده ها
داشبورد VTS از الگوهای دسترسی به داده های زیر استفاده می کند:
- موارد دلخواه کاربر میتوان با استفاده از فیلتر برابری در موجودیتهای مورد علاقه کاربر که شیء کاربر App Engine خاص را به عنوان ویژگی دارند، درخواست کرد.
- لیست تست . پرس و جوی ساده از موجودیت های آزمایشی. برای کاهش پهنای باند برای نمایش صفحه اصلی، میتوان از یک پیشنمایش در شمارشهای عبوری و ناموفق استفاده کرد تا فهرست طولانی بالقوه شناسههای مورد آزمایشی ناموفق و سایر ابردادههای مورد استفاده توسط مشاغل هشدار حذف شود.
- اجراهای آزمایشی پرسوجو برای موجودیتهای اجرای آزمایشی به مرتبسازی کلید (مهر زمانی) و فیلتر کردن احتمالی ویژگیهای اجرای آزمایشی مانند شناسه ساخت، تعداد پاسها و غیره نیاز دارد. با انجام یک پرسوجوی اجدادی با یک کلید موجودیت آزمایشی، خواندن کاملاً سازگار است. در این مرحله، تمام نتایج تست موردی را می توان با استفاده از لیست شناسه های ذخیره شده در ویژگی اجرای آزمایشی بازیابی کرد. این نیز تضمین شده است که به دلیل ماهیت عملیات دریافت دیتا استور، یک نتیجه کاملاً ثابت است.
- مشخصات و داده های پوشش . پرس و جو برای داده های نمایه یا پوشش مرتبط با یک آزمون می تواند بدون بازیابی سایر داده های اجرای آزمایشی (مانند سایر داده های نمایه/پوشش، داده های مورد آزمایش و غیره) انجام شود. یک جستجوی اجدادی با استفاده از کلیدهای موجودیت آزمایشی و اجرای آزمایشی، تمام نقاط پروفایل ثبت شده در طول اجرای آزمایشی را بازیابی می کند. با فیلتر کردن نام نقطه نمایه یا نام فایل، می توان یک نمایه یا موجودیت پوشش را بازیابی کرد. با توجه به ماهیت پرس و جوهای اجدادی، این عملیات به شدت سازگار است.
برای جزئیات بیشتر در مورد رابط کاربری و تصاویری از این الگوهای داده در حال عمل، به رابط کاربری داشبورد VTS مراجعه کنید.